

LESSONS IN JUNOS TROUBLESHOOTING: FIXING A LAN WITH A WEIRD PROBLEM
Regular readers of this blog probably see me as an extremely clever, flawless hunk who knows a lot about networking, never makes mistakes, and is traditionally handsome but with a modern sense of style. And of course, you’re not wrong. Except, here’s the twist: you’re dead wrong.
We bloggers are always keen to share knowledge we’ve learned via books, via real-world configuration, via experience. But one thing we often leave out of the narrative is that this knowledge frequently comes from making mistakes. And of course we don’t go on about our mistakes: after all, it’s embarrassing to publicly admit that we did something wrong. We have to keep up the illusion that we’re smart and great! And that’s a shame, because we all know that our mistakes often yield the greatest lessons. Wouldn’t it be great if we shared not just the lessons we learnt, but the mistakes that led us to the lesson?
With that in mind, today I want to literally make history with my fingers, by writing about a thing I learned the hard way.
Fancy a bonus challenge? Read this post slowly, pause as you go, and see if you can think of troubleshooting steps I might have missed, and what the problem might be. If you can honestly figure it out before you get to the end, I’ll send you $10,000,000 in hard cash. Which, thanks to modern-day politics, translates to about £0.85.
THE SITUATION
On this particular day, my job is very easy: bring up a customer’s new FTTC circuit, using a Juniper SRX as the customer’s router, and make sure it can access other sites in their MPLS VPN.
Spoiler alert: I am incorrect about this job being easy.
A colleague has pre-configured the device. We have an engineer on site to plug everything in. Once the WAN is up, and the LAN is plugged in, all I have to do is confirm that the networks functions as expected, and we’re good to go. It should be a nice, quick, elegant, simple job, that gives us an early finish, and an early trip to the pub.
Let’s say that this network is 192.168.10.0/24. There’s a DHCP pool from .50 to .100. Three machines on the network have static IPs outside of that range. The router is on 192.168.10.1. Nothing fancy, very typical.
The engineer plugs everything in, and the internet connection comes up. Hooray!
We run a speed test, and the speeds are great. Hooray!
He asks the users on site if they have connectivity, and they do. Hooray!
I check the DHCP binding table, and I see about ten machines in there, so I know that all the machines are getting IPs successfully. Hooray!
The engineer can ping other sites in their MPLS VPN. Hooray!
Their wifi works. Hooray!!
Just before we go, we quickly do a test print. And… no luck.
Okay, no problem: it happened before once at a different site, and a reboot cleared any stale ARP entries. So, we reboot, and… aaaand… aaaaaaaaand…. nothing.
Hmm.
THE TROUBLESHOOTING
This particular SRX is set up to use ge-0/0/5 for the WAN. The LAN is spread over five physical ports, ge-0/0/0 to ge-0/0/4, all set as access-mode switch ports, bound to a virtual layer 3 interface of irb.100. However, only one of these ports is being used – they’re actually plugging a 24 port switch into ge-0/0/1. Are you picturing it in your mind? It’s a beautiful picture, isn’t it?
(In case you don’t know, IRB stands for “Integrated Routing and Bridging”, and it’s much like VLAN interfaces on Cisco – what Cisco would call an “SVI”, or “Switched Virtual Interface”.)
For consistency, the IP address of all the printers at every site ends in the same number for the final octet. Let’s say that on this site it’s 192.168.10.5. Usually, I can ping the printer on every site. This time, no such joy. And let’s be clear: pinging printers *is* a joy. A true joy. One of the truest joys known to humankind.
So, I check the ARP cache, and I notice that I actually don’t see any machines outside of the DHCP range. I’ve brought about 20 of this customer’s sites online, and I usually see the three static IP machines in the ARP table. And if I don’t, a ping usually fixes that.
Next, I type “show ethernet-switching table” – and I notice that there’s actually more machines in this table than there are in the ARP cache. That’s interesting: so the SRX knows that the machines exist at a layer 2 level, but for some reason they’re not progressing from the “switch” part of the device to the “router” part of the device.
Out of curiosity, I grab one of the missing MAC addresses, and pop it into a MAC vendor lookup website. Sure enough, the address is owned by the vendor of the printer.
So, our SRX is seeing these static IP machines at layer 2, but not at layer 3. Any ideas yet?
My mind is whizzing. My first thought is that perhaps we’ve got the LAN range wrong. This would explain why the switch is seeing the MAC addresses, but they’re not entering the ARP table – if we’d got the LAN range wrong, then the printer wouldn’t reply to pings, and so it wouldn’t enter the ARP table. Also if the printer was broadcasting ARPs of its own, they’d be ignored by the router, and again, not entered into the ARP cache.
But no: the customer confirmed that 192.168.10.x is indeed correct. Damn! That felt so close.
The engineer on site wondered if there was a problem with the physical setup, and he went above and beyond to try different combinations of cable, to no avail. During that process, he noticed that the cable that plugged the main switch into the SRX was a bit broken – the plastic bit that securely clips the ethernet cable in had come off – but that can’t be the cause of the problem, because DHCP machines have no problems at all pinging other machines on the MPLS VPN network.
Everything seemed fine with the physical network – which is lucky, because the printer was heavier than a tank, and plugging it directly into the router wasn’t an option. Unless we could employ Mr T or Terry Crews for the job. And something tells me that their day-rate might be a little outside our budget.
I wondered if their old setup was on a different, tagged VLAN. But nope: we got the config of their old router, and the setup was very simple.
Okay, time to go deeper, and inspect the traffic on the network for clues.
MONITOR TRAFFIC INTERFACE: A VERY POWERFUL TOOL
I ran the command “monitor traffic interface ge-0/0/1 no-resolve layer2-headers” to see if I could see anything interesting. If you don’t know this command, add it to your toolbox: your friendly Juniper device will report on any traffic destined to, or sent from, the router itself. Not transit traffic, but network control traffic. That means you’re going to see ARP requests, DHCP requests, spanning tree, OSPF, and so on. Have a play with it, and if you like, add the “extensive” knob at the end to get a deep-dive into exactly what’s happening in the packet.
Two things were surprising to me. Firstly, the majority of the traffic I was seeing was spanning tree. There was hardly any ARP at all.
Secondly, the only ARP traffic I actually did see was was from one machine outside of the DHCP range. This machine was calling out to find out where the default gateway was. The SRX replied with an answer, but the host machine didn’t seem to be accepting the answer: it just kept sending the same ARP request out, over and over, every second. What???
I double-check and triple-check the config, and everything seems fine. At my wits end, I pass the config over to a colleague – my boss, in fact – just to give it a second pair of eyes. And when he finds the problem in about 20 seconds, I feel… what’s a word that means feeling even more embarrassed than “extremely embarrassed”?
THE SOLUTION
So here’s a lesson I learned the hard way that day: it turns out that on Juniper routers, you can actually configure virtual (and physical) LAN interface with a /32 subnet mask. Yep: my boss noticed that my IRB interface wasn’t configured as 192.168.10.1/24, as I’d blindly assumed – it was, in fact, set as 192.168.10.1/32.
You can’t do this on a Cisco router. If you try, you get this error:
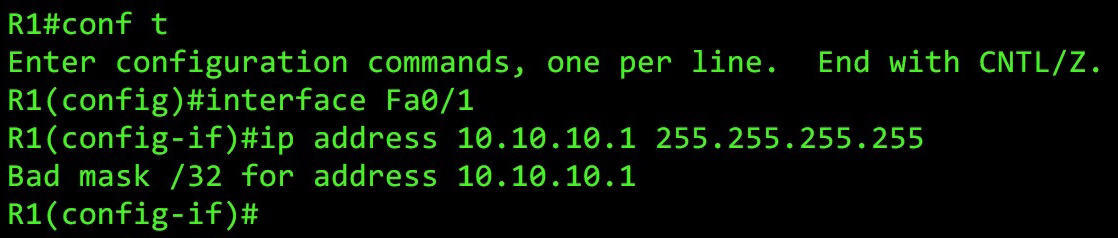
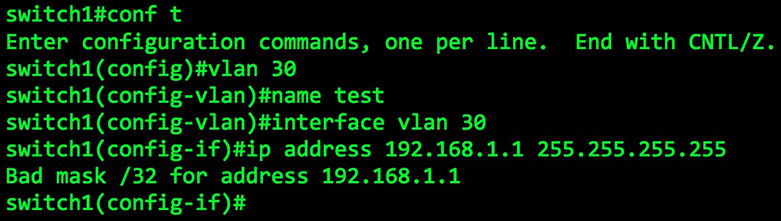
“Bad mask”! Naughty mask! Get back in your bed, mask!!
I must have checked the config from top to bottom about five times over. I checked the mode of the interfaces; I made sure there were no firewall filters; I checked the SRX was in switching mode and not transparent-bridging mode; and of course, I checked the IP address itself so many times. But for some reason, my eyes totally missed that /32.
Because of course they did. I mean, if this LAN was truly a /32, how on earth were other machines on the LAN getting connectivity out to the rest of the MPLS network? Think about it: imagine that a machine with DHCP IP 192.168.50.50 tries pinging 192.168.69.69 (nice). The traffic gets from source to destination with no problem – but let’s think about the return journey.
A packet leaves our destination host of 192.168.69.69 (nice), goes to its default gateway, travels across the MPLS VPN, and arrives at our SRX, which does a routing lookup to find out where 192.168.50.50 lives. Our SRX sees in its routing table a route only to 192.168.10.1/32. That’s not good enough… so, without a matching route, it falls to the default route, and sends it right back down the WAN link, causing us a good old fashioned routing loop.
Except that in reality, this didn’t happen at all. There was no routing loop. In fact, we saw from our testing earlier that the traffic DID make it there back successfully. It didn’t occur to me to check the subnet mask, because how could it be wrong when other traffic was working?
WHAT. WHAT IS HAPPENING. WHAT. LITERALLY WHAT.
It was only when I was in the shower that evening – enjoying some “quality alone time” with my “body” – that it suddenly hit me why this setup works on a Juniper device. And to understand it, we need to talk about something quite unique that Junos does when it gives out an IP by DHCP: it adds a /32 route for that IP into the routing table.
Yep: the subnet mask on the LAN interface was wrong, but it didn’t matter, because our cheeky SRX was adding individual routes into the routing table for all the machines it had given an IP address to. What a scamp!!
Check out this output I labbed up, and definitely didn’t steal from a customer’s live router. Each of these machines was given its IP address automatically – and they’re all in the routing table.
chris.parker@NetworkFunTimes> show route protocol access-internal inet.0: 14 destinations, 14 routes (14 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.10.113/32 *[Access-internal/12] 2d 22:13:14 > to 192.168.10.1 via irb.100 192.168.10.114/32 *[Access-internal/12] 2d 12:43:03 > to 192.168.10.1 via irb.100 192.168.10.115/32 *[Access-internal/12] 2d 12:02:45 > to 192.168.10.1 via irb.100
And as such, when the traffic came from our destination back to us, the SRX had a route not to the whole /24, but instead just to that specific machine that sent the traffic in the first place.
For what it’s worth, Juniper gives this reason for why you’re allowed to use /32s on physical interfaces:

Confession time: based on that short explanation, I’m not entirely sure I understand the advantage. For example, if you’ve got two interfaces that are talking OSPF, and you’re giving each one a /32, isn’t that the same as using a /31? I suppose it gives you more flexibility in the IPs you choose, because if I’m reading that right then the IPs don’t have to be in the same subnet (which is fine for OSPF point-to-points), but I’m not sure that’s a good thing, or a useful. So perhaps there’s something I’m missing.
Having said that, I thought of another reason to use a /32 on a physical LAN interface: if the SRX adds each DHCP machine to the routing table, that means we can configure a /32 on our LAN interface to prevent anyone from joining the network who hasn’t received an IP from DHCP – just like in the problem I had to troubleshoot! If someone tries giving themselves an IP address manually, they’ll have no connectivity to the outside world. Of course, there’s quite a few other ways of achieving that result if you’ve got a fancy switch with DHCP snooping. I can’t imagine this “solution” is anyone’s idea of a best practice. So basically, don’t do this. Unless you want to. But even then, probably don’t. Still: you could if you fancy it?
THE LESSONS LEARNED
That was a pretty stressful day. As you can imagine, I’ve definitely got some takeaways from all this, both on a personal-growth level and on a technical level:
— First of all, if you’ve read a config twice and you don’t see a problem, don’t waste your time: get a friend to look over it. It’s amazing how quickly our eyes and brain become blind to something that we’ve stared at for a while. And hey: if you don’t have a friend nearby, why not ask your enemy’s enemy? They’re your friend too, after all.
— Second of all, when you’re reading a config, a diagram, or some code to check it’s all okay, and you’re still not seeing anything, try reading it out loud, slowly. Say out loud, with your mouth, what you actually see, not what you think you see. This forces your brain to genuinely look at every single little detail, and in doing so it helps you to avoid skimming over bits that you subconsciously just assume will be correct – the bits that are inevitably the problem.
— Third, if the problem seems unusual, trust nothing. Don’t trust your own work, don’t trust your colleagues’ work, give no-one and nothing the benefit of the doubt – not even yourself.
— Fourth, don’t just learn not to make the same mistake again: think about the ways that your troubleshooting failed you, and think how you can speed that up in the future. For example, maybe get that second pair of eyes to look at the config after five minutes instead of two hours. You’ll save everyone a lot of bother!
— Fifth, just because something isn’t possible on one vendor, doesn’t mean it isn’t possible on another vendor. Keep your mind open, and never, ever say the phrase “Well, the configuration is definitely fine”. Because even if you’re 99.99999% sure it is, there’s a 0.00001% chance it isn’t.
— Sixth, related to the one above: Different vendors may adhere to the same RFCs, but they still operate in different ways. If something is happening that doesn’t match your understanding of the fundamental principles of networking, there’s a strong chance there’s some kind of configuration quirk that makes total sense once you know about it. (Equally, there’s a chance there’s just a bug in the firmware!)
— And finally: automation is your friend. Use automation, use it well, and stop mistakes happening in the first place. Don’t make your staff manually configure things: after the 30th router build of the day, it’s too easy for them to type /32 when they mean /24. In fact, I fully plan to spend time learning JSNAPy, so that this entire process can become nice and elegant, and all elements can be tested with just a few key strokes. Embrace our robot overlords, and the reliability and consistency they bring to the automated table.
=============================
Have you got any stories of mistakes you’ve learned from? If you’ve blogged about it, or if you feel like writing about it below, please do leave a comment. I’d love to hear about it!
By the way, thank you so much for reading my blog. If you enjoyed it, you’d make my day if you shared this post on your social media of choice – the more readers I get, the more I want to write even more cool posts for you.
If you’re on Mastodon, follow me to find out when I make new posts. Let’s be internet friends, you and I. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.


