

BGP LABELED-UNICAST ON JUNIPER ROUTERS (FOR JNCIE-SP STUDENTS)
Labeled. Labelled. One is the US spelling, one is the UK spelling. I am British, so I usually write it as labelled, yet I am forced by Google’s merciless algorithms to write it with the American spelling. Now, to be honest with you, I couldn’t care less. We are one human race, ultimately we’re all just made of star stuff, there are more things that connect us than divide us, and I’ve better things to be worried about than which spelling out of two spellings is “correct”. However, for the purposes of the joke: god it makes me mad!!!! The Queen personally told me to spell it as “labelled”!!!!! The networking world makes me feel like a traitor to my country!!!!!
Anyway, regular readers will know that I’m currently doing a three-part series on extending MPLS VPNs between ISPs/autonomous systems. Part 1 on Interprovider Option A, and Part 2 on Option B, were both fairly long, but Part 3, on Option C…. came in at 7,000 words. Duuuuuude, that’s like an entire chapter of a book!
Why was it so big? Because there’s one concept in particular that deserves a lot of attention: BGP Labeled-Unicast. Actually, it can be explained in just a few paragraphs, but if you’re interested in JNCIE-SP certification then you don’t just want a couple of paragraphs: you want a deep-dive. As such, I decided to use my 420-69 IQ, and make a post all on its own about BGP-LU, so you can “prime” yourself for the upcoming guide to Option C.
This post isn’t a complete guide to BGP-LU, but this post does do something that I believe is entirely unique on the internet: it explains not only the default behaviour in Junos of BGP-LU, but also why a certain configuration won’t work – and how to fix it.
WHAT IS BGP LABELED-UNICAST?
If we want a router to advertise a label for something – for example a loopback address, or a prefix in our routing table – then so far we’ve talked about protocols like LDP and RSVP. Or Segment Routing, if you’re new and fancy. But there is another way: using BGP itself to advertise the labels. Do you ever get the feeling that we get BGP to do too much? If I had to work as hard as BGP I think I’d collapse!
A BGP Labeled-Unicast route is just like a normal IPv4/IPv6 route, but with a label. It’s as easy as that! Your router generates this label in exactly the same way that it generates labels in LDP/RSVP, and your lovely router then advertises the route and the label together in the BGP advertisement.
However, rather than advertising this label to the next physical router in the path, like LDP and RSVP do, your router instead passes it to everyone it has a BGP-LU peering with – in other words, to route reflectors and PE routers at the other end of your network. As such, your PE routers will be adding (at least) two labels to get to the other end. First, an inner label for the BGP-LU route. This label stays the same from end to end. Second, an outer label to get to the physical next-hop in the path to the destination. This label changes hop-by-hop, like a regular transport label.
In our post on Interprovider Option B we talked about BGP Address Family Indicators. We learned that IPv4 is AFI 1, and Unicast is Subsequent-AFI (SAFI) 1. Let’s learn about a new sub-address family: BGP-LU is SAFI 4. It’s worth remembering this, so you can talk more precisely about which address family you’re interested in. Unlabled Unicast prefixes are SAFI 1, Labeled Unicast is SAFI 4.
Now, at this stage you might be wondering: fine, but why advertise labels in BGP at all? What’s the use case for this? Don’t we have enough label protocols already? Well, probably yes! But BGP-LU gives us an extra advantage: it allows us to advertise next-hops that we wouldn’t otherwise be able to access.
For example, there’s a technology called 6PE, which lets you run IPv6 on your provider edge routers, but IPv4 in the core. In other words, you can run IPv6 over an IPv4 network that is totally unaware of IPv6! In a few weeks time I’m going to do a post about exactly this topic, and why a label for the next-hop comes in handy to make this happen, but essentially BGP labeled-unicast allows us to advertise IPv6 between PEs, and then send the packet over a path of transit P routers that are totally unaware of IPv6. It’s very cool!
Another example, and the reason I’m writing this post, is Interprovider Option C, where we can extend an MPLS VPN over two autonomous systems (eg two ISPs). By using BGP-LU, we can take the the loopbacks of PE routers and route reflectors, and advertise them between ISPs, with labels. This means we can create full label-switched paths from a PE in one autonomous system, to a PE in another autonomous system!
MIXING BGP LABELED-UNICAST & STANDARD BGP UNICAST
Having read pretty much every single post you’ll see on the entire internet that shows you how to configure Juniper Interprovider Option C, I’ve noticed that almost every post labs it up in a very particular way: they run an example lab which *only* run the “inet labeled-unicast” family on all routers. In other words, in almost every example on the internet, you won’t also see inet unicast in the lab.
This is fine for teaching, for when you just want to keep things simple and show a clean config. But I’ve got to tell you: it confused the hell out of me. Because surely in the real world, people are running both inet unicast AND inet labeled-unicast? We don’t often have PE routers that are just doing VPNs, after all. We usually have a mix of internet and VPN, in different VRFs. So, why are all the examples so siloed? Honestly, I found it so difficult to work out what was going on.
To see if I was going mad, I tried configuring both families on a test router:
set protocols bgp group TRANSIT_ISP family inet unicast set protocols bgp group TRANSIT_ISP family inet labeled-unicast
And to my amazement, this happened:
[edit] root@Router1# commit and-quit [edit protocols] 'bgp' Error in neighbor 11.11.11.11 of group TRANSIT_ISP: peer cannot have both inet unicast and inet labeled-unicast nlri error: configuration check-out failed
Wow. Wow!! Wow. This really threw me. I’ve read a fair bit about BGP-LU, and there isn’t a single place that says you can’t run both at the same time. It’s certainly not mentioned in the RFC. In fact, I even found numerous posts that explicitly say that BGP Unicast and BGP Labeled-Unicast can happily co-exist.
I even tried Googling for that error. And guess what: not a single bloody person on the entire internet has ever faced this problem.
Really? No-one at all? Gosh, it’s lonely being as brilliant as me.
So… what gives?
After a lot – a LOT! – of reading, I finally worked it out. You definitely can run both – it just needs a bit more config. In a moment I’ll tell you exactly what that config is, but first let’s understand why my own config didn’t work. You see, like so many of the posts I make on this website, it all has to do with the distinction between the inet.0 and inet.3 tables.
INET.0 vs INET.3 – THE BATTLE OF THE CENTURY
By default, BGP-LU has the following behaviour. Read these two bullet points a hundred thousand times, because understanding this behaviour is essential for this post:
- If a router learns a BGP-LU prefix, our router will put it in the inet.0 table.
- If a BGP route exists in the inet.0 table, our router will advertise it – with a label.
Now, here’s what’s interesting about this behaviour: if an imaginary Router B is running only “vanilla” BGP with Router A, and only BGP-LU with Router C, then Router B will take the unlabeled prefixes from Router A, put them into inet.0 – and then advertise them with a label to Router C! In other words, Router B actually changes the Subsequent Address Family Identifier from SAFI 1 (Unicast) to SAFI 4 (Labeled-Unicast) when it passes the prefix on to Router C.
Shall we see this in action? You bet your ass/arse we shall!
Let’s do an experiment. In this picture we have ISP 1 – one half of our complete Interprovider Option C topology. There’s a second ISP to the right, configured and working, but not shown. Notice how each router has a loopback IP address that relates to its router number. We’re running a BGP-free core, so our P routers (Routers 2 and 3) are only running an MPLS protocol – LDP, in this case. So, there’s BGP only on Router 1, Router 4, and Reflector 1.
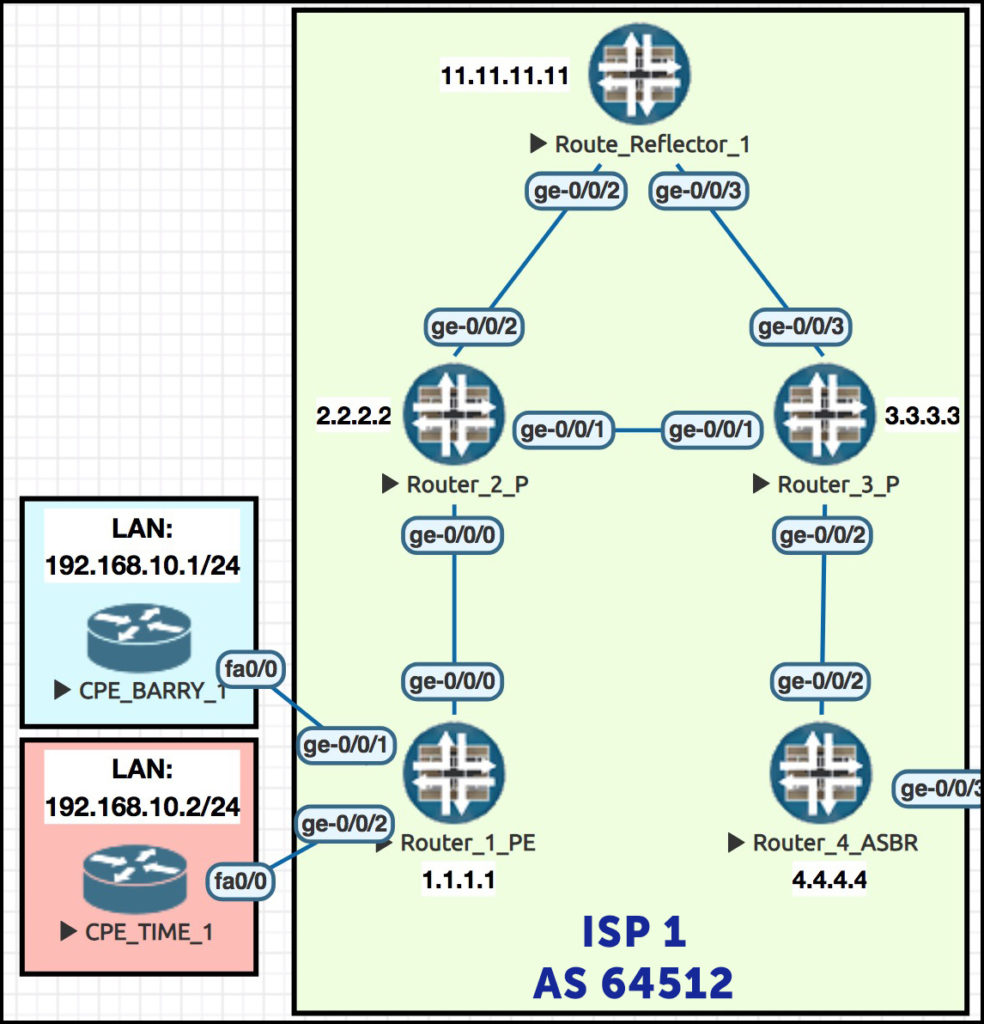
Let’s imagine that we’d turned on only BGP-LU throughout ISP 1. In other words, the peering between Router 4 and Reflector 1, and Router 1 and Reflector 1, are only BGP-LU: AFI 1, SAFI 4. There’s no vanilla BGP Unicast (AFI 1, SAFI 1) in our ISP.
Now, let’s bring in a new Router, Router 9, in AS64514. It has a loopback of 9.9.9.9. Let’s connect it to Router 4, on account of Router 4 being the most handsome and charming of all my routers.

Let’s make an eBGP unicast (NOT labeled-unicast, just regular unicast) peering between R4 and R9. Let’s also redistribute R9’s loopback into BGP.
Router 4 receives this prefix successfully. Note that it’s unlabeled:
root@Router4> show route receive-protocol bgp 10.10.49.9 detail inet.0: 18 destinations, 22 routes (18 active, 0 holddown, 0 hidden) * 9.9.9.9/32 (1 entry, 1 announced) Accepted Nexthop: 10.10.49.9 AS path: 64514 I
Now, let’s be clear: R9 to R4 is standard BGP Unicast. R4 to Reflector 1 is Labeled-Unicast. With that in mind, what does Router 4 do to the 9.9.9.9/32 prefix when it advertises it throughout ISP 1? That’s right: it adds a label! Let’s see how R4 is advertising this prefix to its route reflector at 11.11.11.11:
root@Router4> show route advertising-protocol bgp 11.11.11.11 9.9.9.9/32 detail inet.0: 18 destinations, 22 routes (18 active, 0 holddown, 0 hidden) * 9.9.9.9/32 (1 entry, 1 announced) BGP group AS64512 type Internal Route Label: 299936 Nexthop: Self Flags: Nexthop Change Localpref: 100 AS path: [64512] 64514 I
(Note that R4 would normally need a next-hop self policy to make itself the next hop when re-advertising eBGP-learned prefixes into iBGP. But when you’re re-advertising BGP-U into BGP-LU, it changes the next-hop by default.)
In regards to the label, it’s actually the same label for every prefix that R9 gives to R4, so by default there’s no danger of maxing out your label space by assigning labels for each of the 750,000 prefixes in the IPv4 unicast routing table. As proof, let’s add a second loopback on Router 9, 99.99.99.99/32. Let’s see what routes Router 1 sees as originating from R9:
root@Router1> show route table inet.0 aspath-regex ^64514 inet.0: 15 destinations, 15 routes (15 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 9.9.9.9/32 *[BGP/170] 01:42:28, localpref 100, from 11.11.11.11 AS path: 64514 I > to 10.10.12.2 via ge-0/0/0.0, Push 299936, Push 299840(top) 99.99.99.99/32 *[BGP/170] 00:40:13, localpref 100, from 11.11.11.11 AS path: 64514 I > to 10.10.12.2 via ge-0/0/0.0, Push 299936, Push 299840(top)
There we go: two prefixes, both with the same label.
Router 4 also has a peering to another ISP, with only the labeled-unicast family enabled. As such, Router 4 takes prefixes it’s learned from the other ISP via BGP-LU, puts them into inet.0, and advertises them to Router 9 – without a label. In the output below we see that R9 learns the loopback address of Route Reflector 2, in ISP 2 – with no label, of course!
root@Router9> show route 22.22.22.22 inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 22.22.22.22/32 *[BGP/170] 00:32:22, localpref 100 AS path: 64512 64513 I > to 10.10.49.4 via ge-0/0/0.0
So, with all that in mind – why can’t we configure both “inet unicast” and “inet labeled-unicast” at the same time?
Scroll back up, and note where Router 1 installed those BGP-LU prefixes: it added them to inet.0. As I say, this is the default behaviour. And this is also the reason that we can’t configure both families at the same time. When a router receives BGP prefixes from one particular neighbour, it can certainly put standard Unicast prefixes into inet.0. However, if that router receives Labeled-Unicast prefixes from the same neighbor, by default it cannot also put those same prefixes into inet.0. They have to go into inet.3.
By keeping the two families separate, it allows us to cleanly run both protocols independently, and advertise everything correctly. And so, to run both SAFI 1 and SAFI 4, we in fact have to configure it like this:
set protocols bgp group TRANSIT_ISP family inet unicast set protocols bgp group TRANSIT_ISP family inet labeled-unicast rib inet.3
With this command, we tell BGP-LU to do something different to the standard behaviour: put labeled-unicast prefixes in inet.3. Thanks to this command, we can keep our vanilla unicast and labeled-unicast prefixes totally separate. In fact, we can see this now if we go and check how Router 4 is advertising things to Reflector 1:
root@Router4> show route advertising-protocol bgp 11.11.11.11 inet.0: 19 destinations, 19 routes (19 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 8.8.8.8/32 Self 3 100 64513 I * 9.9.9.9/32 Self 100 64514 I * 22.22.22.22/32 Self 2 100 64513 I * 99.99.99.99/32 Self 100 64514 I inet.3: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 8.8.8.8/32 Self 3 100 64513 I * 22.22.22.22/32 Self 2 100 64513 I
It’s sending everything unlabeled, and in addition it’s taking the two labeled routes it received from ISP 2, and passing them on as labeled routes. Very clean!
ONE FINAL GOTCHA
So far, so good. We’ve got BGP Unicast prefixes in inet.0, available for general use. We’ve got BGP-Labeled Unicast prefixes in inet.3, which BGP-LU can then re-advertise.
 By placing BGP-LU prefixes in inet.3 we’re also allowing MPLS VPNs to resolve their next-hops, and BGP-learned prefixes in general to resolve their next-hops via MPLS label-switched paths. Everything seems to be working #splendidly.
By placing BGP-LU prefixes in inet.3 we’re also allowing MPLS VPNs to resolve their next-hops, and BGP-learned prefixes in general to resolve their next-hops via MPLS label-switched paths. Everything seems to be working #splendidly.
Except… could there actually be a scenario where we do indeed need to resolve a BGP-LU prefix in inet.0? Why, yes there is! We’re going to skip ahead a little to near the end of the Interprovider Option C config here, but I wanted to put this specific gotcha in this post, so that everything is in one place.
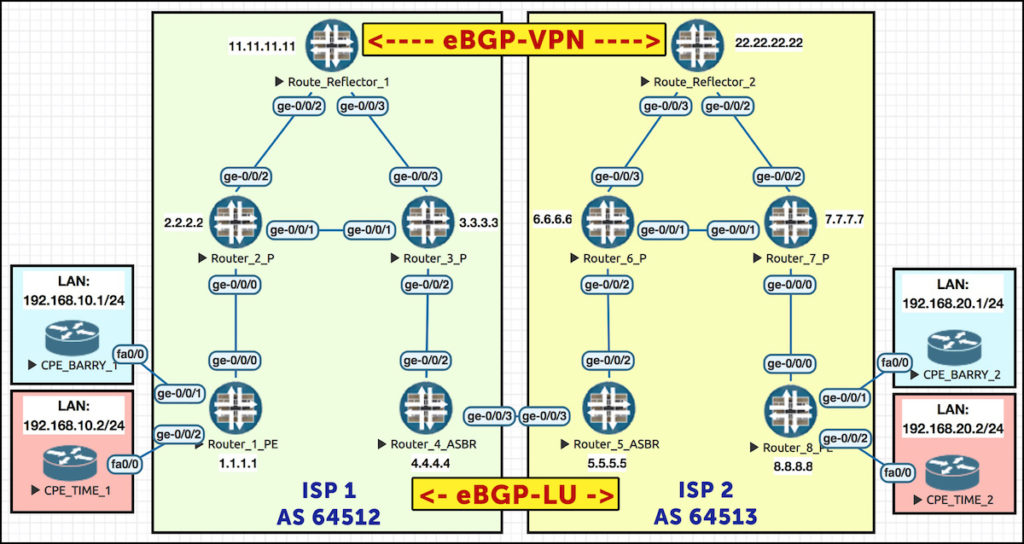
Here’s the full topology that we’ll be using in our upcoming Interprovider Option C post. The most important bit for understanding this gotcha is at the top of the diagram – the eBGP peering between our two route reflectors, Reflector 1 (11.11.11.11) and Reflector 2 (22.22.22.22). This peering is only exchanging inet-vpn prefixes – it’s this peering that advertises the MPLS VPN routes in each ISP to the other ISP.
For reasons that we’ll see later on, Reflector 1 knows about 22.22.22.22 only via BGP-LU. And, thanks to our new command, it places that route in inet.3.
root@Reflector1> show route 22.22.22.22 inet.3: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 22.22.22.22/32 *[BGP/170] 00:12:33, MED 2, localpref 100, from 4.4.4.4 AS path: 64513 I > to 10.10.113.3 via ge-0/0/3.0, Push 300288, Push 299824(top)
However, when we come to build the eBGP peering between the two reflectors – we notice on Reflector 1 that for some reason, the BGP doesn’t actually establish:
root@Reflector1> show bgp summary | match 22.22.22.22 22.22.22.22 64513 403 408 0 2 7:51 Active
I’ll show you the full BGP config in the upcoming Option C post. For now, trust me that it’s correct. I’d never lie to you, or my name isn’t Percibald, King of Japan.
So, what gives? It couldn’t be something silly… could it?
Well, we’ve got a route… but remember what table the route is in – inet.3! To create a BGP peering, Reflector 1 needs to be able to resolve 22.22.22.22 in inet.0.
And here we see the real complexity of running inet unicast and inet labeled-unicast at the same time. Depending on your use-case, it might not be as simple as just saying “put all BGP-LU prefixes in inet.0”, or “put all BGP-LU prefixes in inet.3”. Chances are that we’re actually going to want to selectively leak some prefixes between the two tables, to solve problems just like this.
At this point I must give big shout-outs to the truly brilliant book MPLS in the SDN Era, who teach us the config we’ll use to solve this problem.
Still on Reflector 1, first, we make a policy referring just to 22.22.22.22, the loopback of Reflector 2:
set policy-options policy-statement RR2_LOOPBACK term RR from route-filter 22.22.22.22/32 exact set policy-options policy-statement RR2_LOOPBACK term RR then accept set policy-options policy-statement RR2_LOOPBACK term ELSE_REJECT then reject
Next, we use this policy in a RIB group. RIB-groups (RIB meaning “routing information base) is a way of manipulating routing tables. In this instance we’re going to copy prefixes from inet.3 to inet.0 – as long as the prefixes matches our policy:
set routing-options rib-groups RR2_INTO_INET0 import-rib [ inet.3 inet.0 ] set routing-options rib-groups RR2_INTO_INET0 policy RR2_LOOPBACK
Now, this RIB group doesn’t actually do anything until we apply it somewhere. So where do we apply it? Good news, buster: we’re putting it on the BGP peering Reflector 1 has with the rest of its peers in ISP 1:
set protocols bgp group AS64512 family inet labeled-unicast rib-group RR2_INTO_INET0
Did it work?
root@Reflector1> show route 22.22.22.22 inet.0: 15 destinations, 19 routes (15 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 22.22.22.22/32 *[BGP/170] 00:00:30, MED 2, localpref 100, from 4.4.4.4 AS path: 64513 I > to 10.10.113.3 via ge-0/0/3.0, Push 300288, Push 299824(top) inet.3: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 22.22.22.22/32 *[BGP/170] 00:25:07, MED 2, localpref 100, from 4.4.4.4 AS path: 64513 I > to 10.10.113.3 via ge-0/0/3.0, Push 300288, Push 299824(top)
Well, look at that! 22.22.22.22 now exists in both routing tables. And as such, after a few moments, we achieve something that cavemen only dreamed off: a BGP peering between route reflectors in different autonomous systems.
root@Reflector1> show bgp neighbor 22.22.22.22 Peer: 22.22.22.22+59435 AS 64513 Local: 11.11.11.11+179 AS 64512 Type: External State: Established Flags: <ImportEval Sync>
So, now you know almost everything you’ll need to know about BGP-LU if you want to make Interprovider Option C work. Actually, there is one more little command that you’ll need… but we’ll save that for our next post. Come back next week, and we’ll round everything off with a complete topology, lots of example output, and as always, every single router’s full configuration for you to play with in your own lab!
THANK YOU FOR READING!
It’s interesting that you don’t *need* both IPv4 unicast and IPv4 labeled-unicast families – but it’s very good practice to have them both, and maintain them in different tables.
Technically, this behaviour allows you to use the link connecting your autonomous system as both a link for VPN traffic, and for public internet traffic. However, in most designs it seems to be a best-practice to keep these families on separate eBGP peerings, using multiple links connecting the autonomous systems, not only for redundancy, but for the different families. This gives you a clean separation of families, a clean separation of traffic, it makes it easier to identify QoS requirements, and it means that you know what traffic is going over what links. I’ve never seen this explicitly stated anywhere, it just seems to be implied. Seems like a smart idea though.
Anyway, I’ll see you next week when we take this knowledge, and add the complete Option C configuration.
If you’re on Mastodon, follow me to find out when I make new posts, plus you’ll see a lot of ill-considered, sub-rate opinions on all things networking. You’re welcome! (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.



Really Really amazing explanation.
can i configure an ibgp free core with juniper, cisco and huawei with multiple areas ospf without bgp lu? because i tried and dont worked, however with LU its worked
Hi Bruno. Well, the vendors shouldn’t really matter. The configuration will no doubt be very different, but the underlying protocols are open standards.
When you say that it doesn’t work, what is it that doesn’t work? When you try it without BGP-LU, are the BGP peerings forming? Are you trying to run MPLS VPNS across your BGP-free core? If so, what protocol are you using to advertise labels? If it’s RSVP, have you turned off CSPF everywhere? Perhaps the label-switched paths aren’t forming because the end-point lives in a different area.
hi Chris,
can you do a post with the Carrier Supporting Carrier option in Junos?
Thank you
Sorry for the extraordinary slow reply! I definitely want to, it would be a good way to completely round off the interprovider blog series. I’ll aim to do one sometime in the next few months. 🙂
also, MVPN and EVPN for Mpls? 🙂
Great article! Great Explanation! Thank you..
hi Cris ,
really amazing explanation ….
thanks you so much and keep it up .
Thank you very much! 🙂
hi,
I think this sentence incorrect
It’s sending everything unlabeled, and in addition it’s taking the two labeled routes it received from ISP 2, and passing them on as labeled routes
It should read ‘passing them on as unlabelled routes’ ?
Hi there Suren! Actually, I typed it right. The two prefixes we learn from ISP2 are 8.8.8.8/32 and 22.22.22.22/32, and these are sent as labelled routes. They’re learned as labelled routes from ISP2, and it’s very important that they stay labelled as they’re passed on to Reflector 1. If they weren’t labelled, the end-to-end LSP couldn’t be built.
Hi there,
Cool post – thanks.
One question to nail down the theory and the junos implementation around all this. Would it be possible to know what is the algorithm/logic and what table is used in junos to validate a bgplu nh when in inet0 and/or when natively or copied in inet.3 ?
hey Chris.
So we can do the BGP-LU labelled network without running LDP or RSVP as BGP is taking care of the Label distribution ? Is that the correct assumption ?
If we got only single PE peering with the RR , then do we need LDP or RSVP ? Just a query.
Thanks heaps for the article .
Hi there Deepak,
You do still need LDP or RSVP.
Actually, to be more precise, you don’t need them, but if you didn’t use them then you’d be causing yourself a lot of problems. Imagine a network with six routers, all in a row:
A–B–C–D–E–F
And imagine that F is the border router on your network, that talks to other ISPs. Now imagine that F advertises a BGP-LU prefix to A. In other words F advertises a prefix to A, and that prefix has a label. A still needs to have a labelled path to get to F, and this is what LDP or RSVP would normally achieve.
But imagine if you used BGP-LU instead of either of these. That means you’d have to have a BGP-LU session from A to B, then another from B to C, then another from C to D, and so on. In addition, you’d have to either pretend that each router was its own unique autonomous system so that the prefixes would be passed on, or you’d have to make each router into a route-reflector so that iBGP would pass it on. You can imagine the operational overhead and the complexity it would bring. And for what advantage? Basically none.
So you can see that the answer is: *technically* yes, you could – but please don’t! 😉
Thanks again Chris.
I promise, I won’t 🙂
The reason for my curiosity was , I have a scenario where the my managed PE is peering with RR via other ISP’s L2 network . so was wondering why do i need LDP labels when BGP is already doing the job . No other router in between my PE and RR in this case.
PE (as1) —-( ISP L2 NETWORK ) —> RR1 (as2)
—> RR2 (as2)
Also, can you also add an article on Juniper QoS .
Hey Chris, Excellent article! Good Reading!
Related to Deepak’s query, router A and F (non-RR routers) have labelled path using LDP or RSVP. Can RR1 and RR2 take care of the control plane by ebgp peer with BGP-LU, without LDP or RSVP in an interprovider option C.
Please keep up the great work!
Good article! Funny that you spelled God with lower case ‘g’ and Queen with uppercase ‘Q’.
Haha well spotted!
Hi Chris, great work! Very useful to understand some topics in deep.
“we achieve something that cavemen only dreamed off” LOL I’m still laughing 🙂
Thank you so much.
great article, keep it up!
Thank you so much for this great explanation on BGP Labelled Unicast and its Juniper caveats
😀 Thank you!