

JUNOS ROUTERS: WHAT DOES THE INET.3 TABLE ACTUALLY DO?
Today, in this two-part blog post, I’m going to take you on a magical journey. And by “take you on a magical journey” I mean “teach you what the inet.3 table does, and how to manipulate the way Juniper routers resolve next-hops in BGP/MPLS networks.” Which is basically the same thing as a magical journey, right?
In this first post we’re going to talk about exactly what an LSP is, what inet.0 and inet.3 do, and the situations where we do (and don’t) use them.
Then, in part 2 we’ll talk about some situations when we might want to move IPs from inet.3 to inet.0. We’ll talk about why we might want to copy them, instead of moving them. We’ll talk about how to advertise LSPs as links in your IGP. And we’ll even talk about how to use LSPs to forward all traffic, without it affecting your network in unintended ways.
Until today, all of these concepts were merely the stuff of dreams. Well, Lucy, today your dreams are over.
THE BEGINNING OF OUR STORY: BGP, AND INET.0
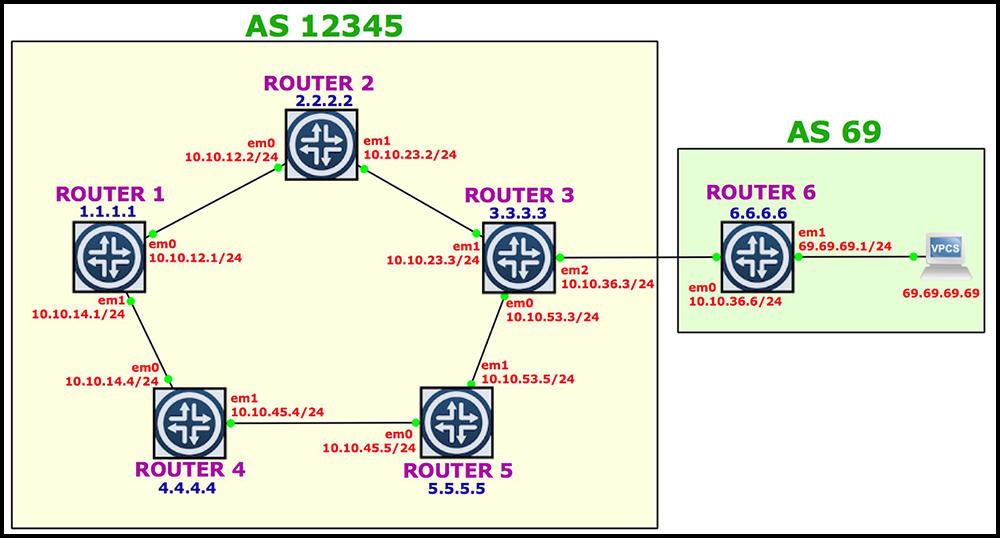
Imagine a network like the one in this diagram. Or better yet, don’t imagine it at all, and instead just look at the diagram with your eyes! Save your imagination for imagining better things, like whether a dragon could ever learn to touch-type, or whether Ban Ki-moon has ever watched Shrek.
Now, you might know about inet.0 already. It’s the “normal” routing table. By default, static and directly connected routes all go into this table, as do prefixes learned by an interior gateway protocol (IGP) like OSPF or IS-IS. And on the whole, when we learn prefixes via an IGP, the next-hop to those IPs will be the router giving us the advertisement. For example, in our diagram, if Router 2 advertises routes to Router 1, R1’s next-hop will be 10.10.12.2, out the directly connected interface to R2.
Routes learnt by BGP also go into the inet.0 table. But next-hops in BGP work a little bit differently.
You see, two routers at either end of a network might have an iBGP relationship, but even though there’s many other routers in between them, the iBGP routers still advertise themselves as the next-hop for any prefix they advertise. Or sometimes, they don’t even do that – it’s possible that they’ll advertise a next-hop of the router that they themselves learned it from! Either way, this means that the router receiving the routers needs to then do a second look-up to work out the actual next-hop, to resolve this far-away next-hop.
 Here’s an example. In our network, every router has an iBGP peering to every other router. Let’s concentrate on Router 1 again, which has an iBGP peering to Router 3.
Here’s an example. In our network, every router has an iBGP peering to every other router. Let’s concentrate on Router 1 again, which has an iBGP peering to Router 3.
R3 is advertising 69.69.69.0/24 (nice) to R1, with R3 – specifically its loopback, 3.3.3.3 – as the next-hop. It does this because we configured R3 with a policy, telling it to make it self the next hop for any routes it learns from R6. By default, R3 would actually advertise a next-hop of 10.10.36.6 – the router it learned about this prefix from.
Now, if R1 thinks it can get to 69.69.69.0/24 (nice) via 3.3.3.3, but 3.3.3.3 isn’t directly connected, then how does R1 get to 3.3.3.3? The answer is that we have to do a second look-up to find out how to get to R3’s address. In other words, we have to resolve this next-hop. And, as it turns out, we know how to get to R3’s address because of our IGP.
Let’s look at some of the “extensive” output on R1 for 69.69.69.0/24 (nice). We actually see two next-hops: the “protocol next hop” (ie the next hop that BGP is advertising), and the actual next-hop (ie where the packet will physically go next).
root@Router1> show route 69.69.69.69 extensive inet.0: 14 destinations, 14 routes (14 active, 0 holddown, 0 hidden) 69.69.69.0/24 (1 entry, 1 announced) TSI: KRT in-kernel 69.69.69.0/24 -> {indirect(131070)} *BGP Preference: 170/-101 Next hop type: Indirect Address: 0x9334c70 Next-hop reference count: 6 Source: 3.3.3.3 Next hop type: Router, Next hop index: 554 Next hop: 10.10.12.2 via em0.0, selected Protocol next hop: 3.3.3.3 {snip}
So far, so good. We’re running protocols, everything is being learned automatically, and everything goes into inet.0. It’s a tradition as old as time itself.
Now, in a moment we’ll make things spicy by turning on MPLS – because when we do, the story is a little bit different. But to understand why, we first need to make sure we’re “A-OK” with the concept of a label-switched path.
SOME QUICK REVISION: WHAT IS A LABEL-SWITCHED PATH?
A label-switched path (LSP) is a pre-agreed path between two routers in a network, that a packet will traverse to get to its destination. The routers all communicate to indicate what label they’d like to receive for traffic destined along that path, and the connected routers will add that label to the packet before sending it. The receiving router strips the label, and potentially puts a new label on as it forwards the packet on further down the path.
Now, if you’ve never done MPLS before, you might think: why would we want this? Don’t our routers already know how to forward a packet? Isn’t that the whole point of a router? Well, for sure it is. But when we create label-switched paths using MPLS, we get some super-cool extra functionality beyond standard forwarding.
For example, we can run Layer 3 MPLS VPNs, because suddenly we can forward by label instead of by IP address, which gives us the ability to have the “same” private IP address belong to multiple customers. We can perform “traffic engineering”, where we create a path that goes a different way to what OSPF or IS-IS tells us is the “best” path. We can automatically calculate backup paths that kick in immediately if there’s a problem in the network. And, a fictional fourth example: we can solve climate change. “Wow”! In that respect, think of an LSP not just as a path, but as a kind of tunnel.
There’s two ways we can create an MPLS label-switched path. The easy way is to use LDP, or Label Distribution Protocol. By simply turning it on, our routers will form neighbour relationships with directly-connected routers, just like an IGP does, and automatically start advertising labels.
When you choose to use LDP, something interesting happens: Juniper routers *only* advertise labels for their loopback IP addresses. That means that if I turn on LDP in our example network, router 1 will learn a label to get to 3.3.3.3, but it won’t learn a label to get to 10.10.23.0/24, the network connecting routers 2 and 3. There’s a reason why it’s only loopback addresses, and we’ll come back to that. Ooh, the suspense!
LDP is very easy and quick to set up, but it doesn’t give us much control; the traffic only follows the best path that we learned from our IGP. That’s where our second method comes in: the Resource Reservation Protocol. In RSVP, we have to manually create all of our LSPs, specifying them by name on every single router in the network. The advantage, though, is that we get a ton of control over exactly what path our LSP takes.
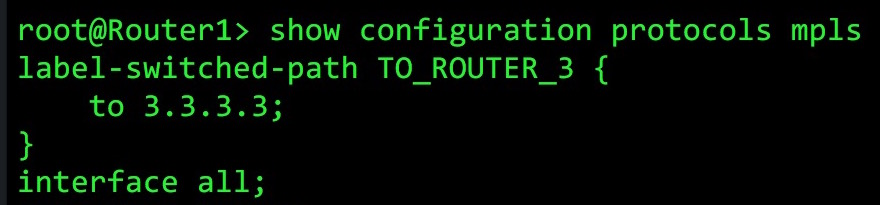 You can see here what a very simple RSVP LSP configuration looks like. Weirdly, it’s configured under “protocols mpls”, not “protocols rsvp”. This is a bare-bones configuration: all I’ve done is create the destination, but I could have done so much more. I could have forced the LSP to go via certain hops; I could have told it to avoid certain links; I could have told it to signal a backup path; to go a different way if the bandwidth goes to high; and tons more.
You can see here what a very simple RSVP LSP configuration looks like. Weirdly, it’s configured under “protocols mpls”, not “protocols rsvp”. This is a bare-bones configuration: all I’ve done is create the destination, but I could have done so much more. I could have forced the LSP to go via certain hops; I could have told it to avoid certain links; I could have told it to signal a backup path; to go a different way if the bandwidth goes to high; and tons more.
Whether we choose to use LDP or RSVP, the information about the LSPs are stored in one of two places: mpls.0, or inet.3. We’ll come back to mpls.0 in a moment. For now, let’s look at inet.3.
A CHALLENGER APPEARS: INET.3.
If a router is acting as the ingress for an LSP (or, to say it in English: if a router is the start of the tunnel, where traffic enters, or “ingresses”, the LSP) then you’ll find the IP address of the other end of the LSP (the “egress” of the tunnel) in the inet.3 table.
Let’s look in the inet.3 table of Router 1. I’ve turned on LDP on all interfaces on all routers, which means that I automatically have an LSP to the loopback of every router in my network. In addition, I’ve manually created one RSVP LSP, directly to Router 3. Let’s take a look at what we see:
root@Router1> show route table inet.3 inet.3: 4 destinations, 5 routes (4 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 2.2.2.2/32 *[LDP/9] 00:00:09, metric 1 > to 10.10.12.2 via em0.0 3.3.3.3/32 *[RSVP/7/1] 00:56:03, metric 20 > to 10.10.12.2 via em0.0, label-switched-path TO_ROUTER_3 [LDP/9] 00:00:09, metric 1 > to 10.10.12.2 via em0.0, Push 299952 4.4.4.4/32 *[LDP/9] 00:00:04, metric 1 > to 10.10.14.4 via em1.0 5.5.5.5/32 *[LDP/9] 00:00:04, metric 1 > to 10.10.14.4 via em1.0, Push 300016
So, a few fun facts. First of all, notice that the *only* IPs we see in this table are the loopback addresses of our other routers. Again, we’ll come back to why this is. Ooh, isn’t the suspense just killing you?
Second, we see two entries for 3.3.3.3: the LDP-signalled LSP, and my manually created RSVP path, which I cleverly called “TO_ROUTER_3”. You can see from the * sign that the RSVP path is being chosen. RSVP has a route preference of 7, whereas LDP has 9, so RSVP paths will always get chosen over an LDP path by default.
Third, on some of these routes we can actually see the exact label that will be “pushed” onto the packet as it goes out of the interface. (The RSVP route does’t show a label, for space reasons, but we could see this label if we added the “extensive” keyword.) However, we don’t see a label for 2.2.2.2 and 4.4.4.4.
This is because these routers are directly connected to Router 1, and by default MPLS doesn’t bother adding labels for packets destined to directly-connected routers. You may have heard of this behaviour before: it’s called Penultimate-Hop Popping (PHP), and it is hands-down my favourite phrase in the whole of IT. In fact I fully plan to name my first-born child Penultimate-Hop Popping. I will do this regardless of how angry it makes my family, and no government in the world can stop me.
Anyway, PHP is generally a good thing. If you’re the penultimate route in the LSP, you’re doing a favour to the router acting as the egress of the LSP by “popping” the label before sending your packet. If there was a label, the egress router has to do twice the work, because it has to look up the label, see the packet is destined for itself, pop the label, and then do a second lookup on the IP address. By using PHP, we’re making things a bit more efficient.
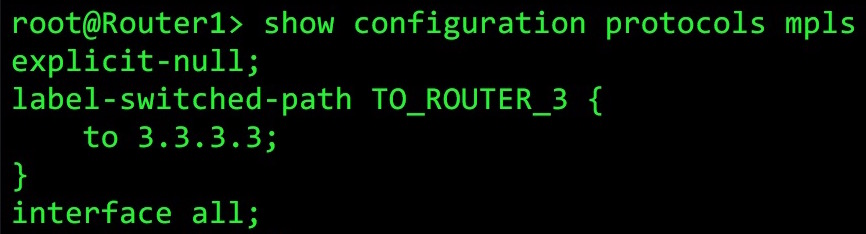
However, we can actually turn on labels everywhere with the “explicit-null” command. As you can see below, when we turn this on, we see a label of 0 for packets destined to a router that is the egress for the LSP:
2.2.2.2/32 *[LDP/9] 00:00:03, metric 1 > to 10.10.12.2 via em0.0, Push 0
This can be useful for a few things, for example if you’re carrying QoS information in the MPLS header. By keeping the MPLS header to the very end, QoS information can be carried all the way.
OKAY COOL, BUT: WHAT IS INET.3 ACTUALLY USED FOR?
So, now our router 1 (and I do consider it to be *our* router) knows about a label-switched-path to the IP address 3.3.3.3. This means that if I were to ping 3.3.3.3 from router 1, the outgoing packet would have a label attached to it, right? The traffic would go down the label-switched-path, right? Right? Well… no, not quite.
You see, in Junos the inet.3 table has one very specific job: to resolve BGP next-hops.
Here’s the key thing to understand: whenever a Juniper router learns a route by BGP, Junos needs to decide how to get to the protocol next-hop. And to get the answer to that, Junos looks in both inet.0 (where the “regular” IP addresses are), and inet.3 (where the labelled paths are). It considers both tables, but by default RSVP and LDP have a much lower route preference than OSPF or IS-IS, so the labelled path will always win.
Note that by default, this is only for BGP-learned traffic. In other words, traffic destined *to* 3.3.3.3 will NOT take the label-switched path. In fact, it will just go out of the router as a regular packet. But, if:
- There’s a prefix in the regular inet.0 table
- Learned via BGP,
- With a protocol next-hop of 3.3.3.3,
- And if the BGP next-hop is in the inet.3 table,
- THEN that traffic WILL take the label-switched path.
Just in case you don’t quite understand, let’s look at an example.
Once again, in our diagram R1 is learning about the 69.69.69.0/24 network (nice) by BGP from R3. First, remember what happened earlier, with no MPLS. Router 1 receives a packet destined to 69.69.69.69 (nice). R1 looks in inet.0, and sees it has a match for the 69.69.69.0/24 network (nice), learned from 3.3.3.3. R1 then does a second lookup, and discovers that it can get to 3.3.3.3 via 10.10.12.2. R1 then pushes the packet out as a normal IP packet.
Now, let’s run the same scenario, but with MPLS turned on.
Router 1 once again looks up 69.69.69.0/24 (nice), and sees that it’s learned about this prefix via BGP, from 3.3.3.3. But this time, Router 1 knows that it actually has a label-switched-path to 3.3.3.3. It knows this because it looked in inet.3.
So, R1 sends the packet out, but this time with a label saying that it’s destined to 3.3.3.3. We can see this label by looking a the extensive output for the route:
root@Router1> show route 69.69.69.69 extensive inet.0: 14 destinations, 14 routes (14 active, 0 holddown, 0 hidden) 69.69.69.0/24 (1 entry, 1 announced) TSI: KRT in-kernel 69.69.69.0/24 -> {indirect(131070)} *BGP Preference: 170/-101 Next hop type: Indirect Address: 0x9334c70 Next-hop reference count: 6 Source: 3.3.3.3 Next hop type: Router, Next hop index: 544 Next hop: 10.10.12.2 via em0.0 weight 0x1, selected Label-switched-path TO_ROUTER_3 Label operation: Push 299904 Label TTL action: prop-ttl Protocol next hop: 3.3.3.3 {snip}
So, where did this label 299904 come from? Well, R2 actually told R1 that this is the label it wants to receive. And to know what R2 does with this label, we introduce the other routing table of interest to us: mpls.0.
The mpls.0 and inet.3 tables have similar but distinct tasks. In inet.3 you’re going to find all the LSPs for which this router is acting as the “ingress” – in other words, the start of the tunnel. This is why BGP uses this table to resolve next-hops. By contrast, our mpls.0 table is used when we receive a packet that has a label on it already. In other words, think of mpls.0 as the routing table for any LSPs where we’re acting as a “transit” router, ie a router in the middle of an LSP.
Let’s have a look at what router 2 does when it receives a packet with label 229004:
root@Router2> show route table mpls.0 label 299904 mpls.0: 12 destinations, 12 routes (12 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 299904 *[RSVP/7/1] 10:00:04, metric 1 > to 10.10.23.3 via em1.0, label-switched-path TO_ROUTER_3 299904(S=0) *[RSVP/7/1] 10:00:04, metric 1 > to 10.10.23.3 via em1.0, label-switched-path TO_ROUTER_3
Ooh: it knows the name of the LSP we configured on R1! That’s the magic of RSVP, baby!!
If we were to look into the extensive output of this label, we would see the label that Router 2 will put on this packet as it sends the packet on its way. In fact, because the next hop is R3, ie the final hop, we would see that the label is being “popped”, because of penultimate-hop popping. The packet is sent out unlabelled, because the packet is being sent to its final destination.
(Fun bonus fact: (S=0) refers to whether the “bottom-of-stack” bit has been set in the MPLS header. If S=1, the label is the bottom of the stack. If S=0, then there is one or more labels “underneath” this one. For example, this “top” label might tell the router where to forward traffic, whereas the “bottom” label might tell the egress router which MPLS VPN the packet belongs to.)
WHY DOES ONLY BGP USE INET.3?
Now, you may be wondering: why is it only BGP that gets to use inet.3 to resolve next-hops? What’s so special about BGP? Did it bribe its way into the LSP’s heart? Did BGP’s dad go to school with MPLS’s dad? It’s always who you know in this business, isn’t it?
It might seem odd at first, but there’s actually a few good reasons. The first is a simple one: OSPF and IS-IS are getting their next-hops from a router that’s directly connected to it, so it doesn’t need a label-switched-path.
(At this point in the post, let’s say explicitly what I’ve so far just implied: the reason that Junos doesn’t (by default) advertise labels for its physical interfaces, and only advertises labels for its loopback, is because BGP advertises the loopback as the next-hop – and on the whole, we tend to only want to send traffic down label-switched paths if the destination was learned by BGP.)
Another reason: it’s common in large ISPs to actually run a network with a BGP-free core – in other words, not every router will actually be running BGP. MPLS allows traffic to travel across a core network that is actually completely unaware of how to get to the IP addresses in the packet! Again, this won’t be the case with OSPF and IS-IS, which are protocols that will definitely be running throughout our network.
A final example is MPLS VPNs (which are of course advertised by BGP). The labels are used to distinguish between two different customers – customers who may even be using the same private IPs. In addition, the use of labels means that our core routers don’t need to know anything about our VRFs. We can run Layer 3 VPNs, Layer 2 VPNs, VPLS and so on, all running at the edge of the network, with our core routers totally unaware.
So, most of the time the inet.3 table is only needed by BGP. But of course, *most* of the time doesn’t mean *all* the time. Wouldn’t it be good if we could change this default behaviour? Wouldn’t that just be awesome, and the best thing ever?
Well, guess what: I’ve drunk two bottles of gin today!
Also guess what: there are many, many ways to change this default behaviour, each with their own upsides and drawbacks. Some of these ways you’ll use in the real world, and some of them are really just corner cases to fix specific occasional problems. And in part 2, we’re going to talk about exactly that.
Click here for part 2, where we learn how to totally change everything we’ve read about. We’ll be moving things between inet.0 and inet.3 so much that you won’t even know what planet you’re on any more.
———
Thank you so much for reading this! I hope my blog has taught you something new, and maybe given you some smiles along the way. If you found it useful, you’d make my day if you shared my post on your favourite social media of choice. The more people that read my blog, the more I’m inspired to write even more, and share my passion for networking and Juniper.
If you’re on Mastodon, follow me to find out when I make new posts. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.



Hi Chris! Where you mention turning on MPLS and hey-presto our BGP traffic will follow an LSP to its destination – isn’t that only the case where next-hop-self is used in iBGP? Without it, BGP traffic will still be normal, as the next-hops won’t be loopbacks?
Or am I way, way wrong here?
Cheers!
Hi James! Forgive me, which part of the post do you mean? I’ll definitely change that if I said it, but I’m not sure where I said it. Could you quote the bit you mean please? Thank you!
Hi Chris,
This was really useful and fun. Thanks and appreciate your efforts.
Regards,
Ayman
Really helpful Chris
Thanks
Thank you mate! 🙂
Hi Chris,
I would like to know why Juniper routers *only* advertise labels for their loopback IP addresses?
Hi Mohammed,
I’ve added this sentence to the blog, which will hopefully help clear things up:
“The reason that Junos doesn’t (by default) advertise labels for its physical interfaces, and only advertises labels for its loopback, is because BGP advertises the loopback as the next-hop – and on the whole, we tend to only want to send traffic down label-switched paths if the destination was learned by BGP.”
Hey Chris!
Congratulations, very good explanation with some useful tips of why things happen, very well written and with a nice sense of humor!
Keep writing!
Thank you very much! 🙂
Hey Chris,
I’m a fan of your cool Junos posts? I was literally looking for the “what is the use of the inet.3 table juniper” in google and this magic post came up. Being new to MPLS and reading your posts has been very helpful to understand the “why” behind lots of MPLS related concepts.
Thanks,
B
You’re very kind to leave all these wonderful comments. Thank you very much!
Chris, absolute masterclass, thank you for this!
Chris,
This is really AWESOME description. Packed with details, yet very simplified and easy to follow.
Al.
You are very kind Adel, thank you very much!
nice, clear!
Thanks so much for this!! You are the man
I wish I had read this post before reading other things on mpls, ldp and inet.3 table. This is gem of a post. Thank you.
Hi Chris, I’ve been working my way through your posts and I want to thank you for some amazing info in a fun to read format.
I know your focus is on junos but does the construct of the inet.3 table exist in IOS-XR or is it just a single inet table with recursive lookups?
Thank you very much! I’m afraid I know very little about IOS-XR, but I can definitely recommend giving the book MPLS in the SDN Era a read. The book covers both Junos and IOS-XR, and shows you the equivalent configuration and verification commands for both systems.