

Route Distinguishers: The Secret To Load Balancing In Multihomed MPLS VPNs
It’s amazing how many things humans have invented. Trousers, flags, door bells, frying pans, saxophones, trees, calculators – all of them invented by human beings like me and, to a lesser extent, you.
As it happens, I’ve invented a few things myself over the years. For example, you know when you cross the road? You know how there’s always that one bit of the pedestrian crossing that smells like grandma? That was my idea. They call it the Memory Square, and it’s a nice way to stop for a few minutes while you’re crossing the road, and let the aroma remind you of childhood.
The other thing I invented was a time travel machine. Sadly, the machine gained a sentience greater than you could possibly imagine, and it transported itself to the day that “Oh Carolina” by Shaggy was released. I hear that every 24 hours it transports itself back to the start of the day, like a voluntary Groundhog Day, relieving the objectively happiest moment in history. My only regret is that my time machine didn’t take me with it. Then again, I don’t blame it. After all, I wouldn’t take me with me either!!!! Hahaha!! Haha! Ha! Ha.
Anyway, forget I said any of that, because today we’re here to talk about a different invention: MPLS Layer 3 VPNs. And more specifically, route distinguishers.
We’ve talked before about what route distinguishers are, and how they’re different from route targets. If you’re reading this post and you don’t yet know the difference between them – stop right there, buster! That’s mandatory knowledge before you carry on. Lucky for you then that I wrote this post explaining the difference. Give that a read first, because there’s some base level knowledge you need to understand this post.
Read it? Good job! Right. With that out of the way, today I want to talk about the three different kinds of route distinguisher – and why one of them gives you some awesome advantages. Let’s get familiar with the topology this post uses, and then jump into some real nice concepts. Real nice. REAL nice!
OUR TOPOLOGY FOR THIS LAB
Hey look: it’s the return of the famous ten router lab! What makes it famous, you ask? Really? You’re asking that? Wow. Wow. So you’re telling me you’re not aware of the charity work my famous ten router lab has been doing, to give an iPod to every dog in the world? Wow. Maybe you need to start reading a newspaper now and again, yeah? smdh
I highly recommend opening this pic in a new tab, so you can have it by your side as you read this. Understanding which router is talking to which router will be crucial as you progress through this post.
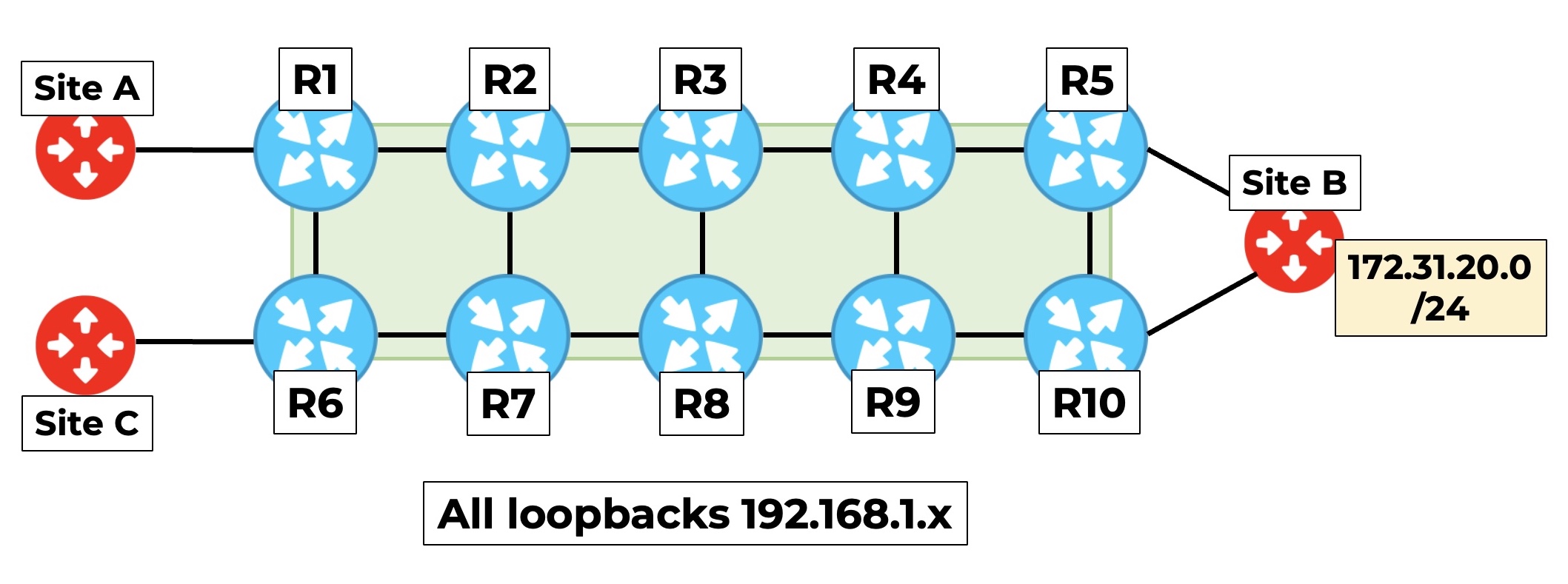
There’s four BGP-speaking edge routers in this network: R1 and R6 on the left, and R5 and R10 on the right. At various points in this post you’re going to think of advertisements being sent and received from the perspective of these four edge routers, so take a moment to look at this topology, and get a feel for where they are.
To begin with, all four edge routers will talk BGP to each other directly. Then, later on we’ll “shake things up” and make R8 a route reflector, to see how your choice of route distinguisher can have a big impact.
Site B is advertising a prefix to both R5 and R10, who then re-advertise it to the other internal BGP speakers. Happy with that? Excellent. Then let’s begin. I love you. What? No, I didn’t say anything. Must have been the wind maybe.
A REFRESHER: THE PURPOSE OF ROUTE DISTINGUISHERS
Imagine that we’re a service provider, providing MPLS layer 3 VPN services to some customers. How many customers? Choose your favourite number. Is it that many? Absolutely not: It’s two. We’re providing VPN services to two customers. (Unless two is your favourite number, in which case I just changed it to three.)
Let’s imagine that these two customers are using the private prefix of 172.31.20.0/24. And, as chance would have it, they’re both connected to R5. Wow, it’s almost like I planned it!
If R5 advertised these two prefixes to R1 as regular IPv4 prefixes, then R1 has no way of identifying that these are two “different” prefixes, for different customers.
Think of it like this: R5 sends 172.31.20.0/24 to R1, with some unique attributes like a particular local preference, a particular MED, at least one route target that’s unique to customer A, and maybe some other BGP communities. Then, R5 sends 172.31.20.0/24 to R1 again, maybe with a different local preference, maybe with the same MED, certainly with a different route target, one that’s unique to customer B.
How is R1 to know that this second version of the prefix isn’t just an update, a correction of the previous advertisement? R1 has no way of knowing this. If it weren’t for route distinguishers, R1 would just delete the previous version of 172.31.20.0/24, and replace it with this new version.
As you know from reading my other post, that’s where route distinguishers come in.
Route distinguishers are a big long number that we put in front of the prefix, so that the two customers can each have their own “unique” version of the prefix.
R1 no longer sees two copies of 172.31.20.0/24. Instead, R1 will see something like these two advertisements:
64512:111:172.31.20.0/24 64512:222:172.31.20.0/24
We’ll talk about how to read the numbers before the prefix in a moment, For now, just know that from R1’s perspective, these big long numbers have zero meaning. No meaning at all. They’re just a bunch of random numbers, with one and only one purpose: to make the two different advertisement unique. In other words, to “distinguish” between the two routes.
HOW IS A ROUTE DISTINGUISHER BUILT?
A regular IPv4 prefix is four bytes long.
By contrast, A VPN-IPv4 prefix is 12 bytes long, because of the route distinguisher in front of it.
Math(s) fans among you will have therefore deducted that a route distinguisher is eight bytes long. Wow, that’s pretty big, right? A route distinguisher is twice as big as the IPv4 address itself!
Why is it so big? To answer that, let’s take a closer look at what a route distinguisher looks like.
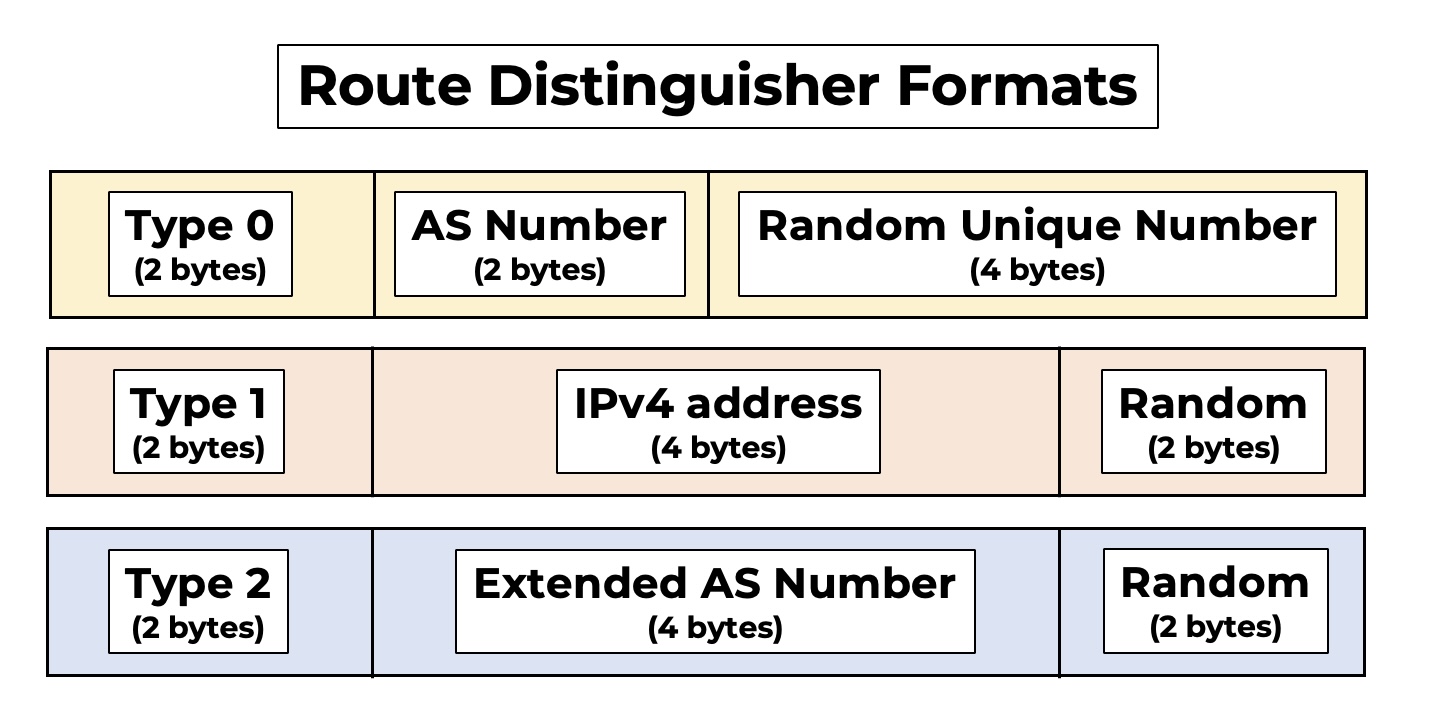
There’s three elements that make up the eight-byte route distinguisher.
- They start with a two byte “type” field. Despite the fact that this is two entire bytes long, this number is only ever 0, 1, or 2.
- Next, there is “some number that is unique to the service provider”. You actually have two choices here. This number can either be the SP’s autonomous system number, or it can be the loopback IP address of the PE router that advertised the VPN prefix. This decision is going to play a big part of this blog post, so we’ll definitely talk more about this shortly.
- Finally, there is a completely random number that has no special meaning, and is there purely to make the prefix truly unique.
It’s interesting that we say that this final “random unique number” has no special meaning – because actually, from the point of view of R1, receiving this prefix from R5, the entire route distinguisher has “no special meaning”. You and I can look at the route distinguisher and maybe identify an AS number, maybe identify an IP address. But R1 doesn’t do that, and R1 couldn’t care less. This can’t be stressed enough: from the point of view of a receiving PE, the entire route distinguisher is just a random number that makes the prefix unique.
So: there’s a type, there’s a bit for the service provider (the “administrator” field), and then there’s a random number (the “assigned number” field).
If the service provider is using a “traditional” two-byte AS number, then the “completely random number” can be four bytes long. However, if the service provider is using a four-byte AS number, or a four-byte IPv4 address, then the “completely random number” can only be two bytes long. That’s still 65,535 potential VPNs on a single PE though, which should be more than enough. The average PE is going to run out of memory, or hit some kind of limit on the number of VPN routing tables it can store, before it runs out of potential random numbers.
And remember, the randomness is all from the point of view of one PE. There’s absolutely no requirement at all for two PEs, hosting the same VPN, to also use the same route distinguisher. Did I mention that this number is random and meaningless?
WHAT DOES A ROUTE DISTINGUISHER LOOK LIKE?
When you write out a route distinguisher, you don’t need to write out the type field. All routers that I’ve ever seen work that out for you, based on how you type it. That means that the following three are examples of how we would write route distinguishers:
64512:111 192.168.1.5:111 4200000000:111
Those are Type 0, Type 1, and Type 2 respectively. Like I say, the type number is implied from the format The type numbers come from RFC 4364, which is the RFC that defines MPLS layer 3 VPNs.
So for example, if we assigned that first route distinguisher to a VPN, then a PE would take 172.31.20.0/24 for Customer A, and advertise it as 64512:111:172.31.20.0/24. Remember that nothing about this RD indicates anything about what VPN the prefix is from. As far as the receiving PE is concerned, it’s just a random number.
If you were using the Type 1 style, then the prefix would be advertised as 192.168.1.5:111:172.31.20.0/24. Again, to the receiving PE, the “192.168.1.5:111” part is completely random and meaningless – though you and I can look at that number and identify the PE it came from.
And finally, the Type 2 style would be 4200000000:111:172.31.20.0/24.
So, which one should you choose? Well, let’s assume you’re using a two-byte AS for now. Should you choose Type 0 or Type 1 route distinguishers? Let’s take a look.
TYPE 0 ROUTE DISTINGUISHERS
Type 0 are the ones that have a two-byte AS number in them, which means you’ve got four entire bytes for your “unique number”.
To pick R5 as a random example, let’s remind ourselves how a VRF in Junos is configured. Below you can see it both in hierarchy format and set format.
To break it down: we’re defining this routing instance as a VRF, we’re putting the customer interface into it, we’ve defined a route target and a route distinguisher, and we’re running OSPF from PE-to-CE. You could equally use BGP, or even static routes. The policy in this config redistributes the PE-to-PE BGP routes into PE-to-CE OSPF routes.
root@R5> show configuration routing-instances VPN_A { instance-type vrf; interface ge-0/0/9.0; route-distinguisher 64512:111; vrf-target target:64512:111; protocols { ospf { area 0.0.0.0 { interface ge-0/0/9.0; } export CUST_BGP_TO_OSPF; }}} root@R5> show configuration routing-instances | display set set routing-instances VPN_A instance-type vrf set routing-instances VPN_A protocols ospf area 0.0.0.0 interface ge-0/0/9.0 set routing-instances VPN_A protocols ospf export CUST_BGP_TO_OSPF set routing-instances VPN_A interface ge-0/0/9.0 set routing-instances VPN_A route-distinguisher 64512:111 set routing-instances VPN_A vrf-target target:64512:111
All four PEs – R1, R5, R6, and R10 – are configured to use a route distinguisher of 64512:111. The number to the left of the colon is the two-byte AS number. The number on the right is just 111, but it could be anything up to 4.2 billion! And again, although I’ve used 111 on all four routers for consistency, I could have typed any number.
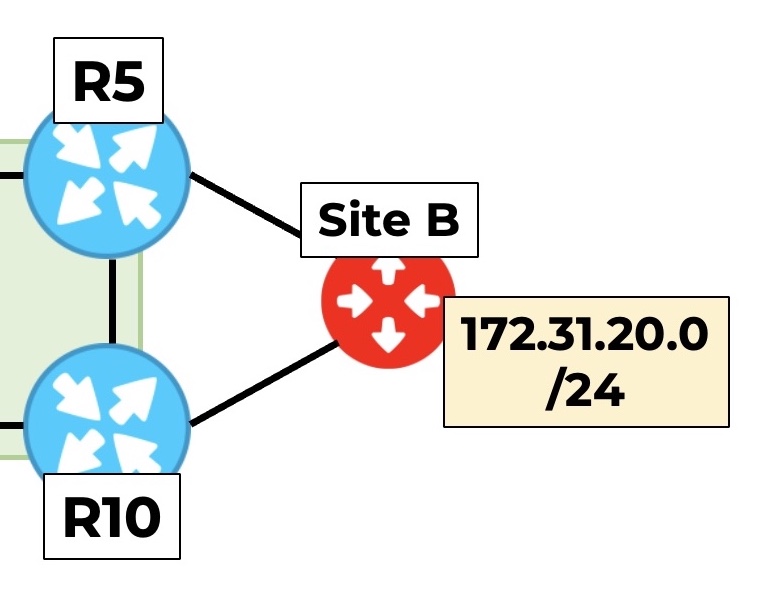 Let’s hop over to R6 and see what this looks like, when it receives advertisements for the 172.31.20.0/24 prefix.
Let’s hop over to R6 and see what this looks like, when it receives advertisements for the 172.31.20.0/24 prefix.
Remember, as you can see in this picture, that Site B hosts this prefix, and it is multihomed to both R5 and R10. This means that both R5 and R10 learn this prefix, and that both R5 and R10 advertise it to the rest of the network.
Another important thing to remember is that there are currently no route reflectors. This means that R6 learns this prefix directly from R5, and directly from R10.
Below you can see that we’re typing the command “show route 172.31.20.0/24 exact”. This shows us all entries for this prefix in all routing tables. (I lied to you: in this lab there’s only one customer, to keep things simple.)
If you look closely below, you can see two routing tables. Give the output a read, and I’ll explain what’s going on afterwards.
root@R6> show route 172.31.20.0/24 exact VPN_A.inet.0: 18 destinations, 25 routes (18 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.31.20.0/24 *[BGP/170] 00:01:22, MED 1, localpref 100, from 192.168.1.10 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10 [BGP/170] 00:01:26, MED 1, localpref 100, from 192.168.1.5 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5 bgp.l3vpn.0: 13 destinations, 20 routes (13 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 64512:111:172.31.20.0/24 *[BGP/170] 00:01:22, MED 1, localpref 100, from 192.168.1.10 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10 [BGP/170] 00:01:26, MED 1, localpref 100, from 192.168.1.5 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5
Starting at the bottom, there’s a table called bgp.l3vpn.0. This is the table that Junos uses to store every single received L3VPN prefix that matches a locally configured route target.
(The default behavior on a Junos router is to discard prefixes that don’t have a matching route target in at least one VRF. This is a good thing, because if your router stored prefixes for VPNs it doesn’t have locally configured, you might run out of memory pretty quickly! There’s no need to keep such prefixes, because if you ever configure a new VPN in the future, your PE can very quickly find out if other PEs have prefixes for that VPN.)
Can you see that there’s an entry in this table for “64512:111:172.31.20.0/24”? This is what the prefix looks like when R6 receives it.
You can see that R6 is receiving this exact prefix (the “prefix” in this case means the full thing, including the RD) from both R10 (you can see that the output says “from 192.168.1.10”) and from R5 (“from 192.168.1.5”).
These two PE routers are advertising exactly the same prefix, from the same VPN customer. In this case, the fact that they’re coming from two different PEs means that R6 can keep both of these advertisements in the routing table. However, only one of them will be chosen as “best”, for forwarding.
You can also see a table called VPN_A.inet.0, which is the customer’s VRF. Notice in this table that the route distinguisher is stripped. Once it’s in the customer’s unique VRF, the RD is no longer needed.
In this table, the advertisement from R10 has an asterisk next to it, which means that BGP decided R10’s prefix is the “best” one of the two. Both advertisements have a lot of things that are equal, so R6 chose the one with the best IGP metric. If you look at the topology you’ll see that R10 is closer to R6, which is why R10’s advertisement is the winner.
It’s handy that R6 still keeps R5’s advertisement. If the prefix from R10 ever disappears, R6 can immediately use the prefix it learned from R5. Nice!
There’s one final thing I want you to know. Later in this post I’m going to show you how to turn on load balancing between these two prefixes. It involves a bit of tweaking, so we’ll put that to the side for a moment. For now, just know that it’s theoretically possible for R6 to load balance between these two advertisements from R5 and R10.
THE PROBLEM WITH USING THE AS-NUMBER IN ROUTE DISTINGUISHERS
Tons of documentation and training uses Type 0 or 2 RDs. But in fact, there’s a problem with them – and it’s such a big problem that once you see it, you’ll probably want to avoid them altogether!
To see the problem, let’s bring a route reflector into the mix.
Our four Provider Edge routers – R1, R5, R6, and R10 – no longer peer with each other, and instead only peer with R8, who is our plucky route reflector from now on. If you didn’t listen to me when I told you to keep the topology open in a new tab, then 1) apologise to yourself, 2) apologise to me, and 3) click here to open it in a new tab.
Everything is configured perfectly, and working as expected. Let’s just double-check that R6 is still receiving this /24 prefix.
(Don’t be confused when you see “from 192.168.1.8” in the output below. This means that this advertisement came from R8, the route reflector, but it doesn’t mean that R8 originated it. The BGP protocol next-hop is still R5 or R10. Keep an eye on the name of the label-switched path to see the originating PE.)
root@R6> show route 172.31.20.0/24 exact VPN_A.inet.0: 18 destinations, 18 routes (18 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.31.20.0/24 *[BGP/170] 00:00:24, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10 bgp.l3vpn.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 64512:111:172.31.20.0/24 *[BGP/170] 00:00:24, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10
Hmm. That’s odd. Do you notice something different? Suddenly the output seems a lot shorter.
On closer inspection, R6 still has the route to R10 for this prefix – but the route to R5 is gone. What’s going on here? Is our route reflector broken?
On the contrary – the route reflector is working exactly as expected.
To show you this, let’s go over to R8’s bgp.l3vpn.0 table. (By the way, R8 has no VPNs configured. However, route reflectors keep all prefixes by default, which is why R8 has accepted these prefixes.)
root@R8> show route 172.31.20.0/24 exact bgp.l3vpn.0: 16 destinations, 23 routes (16 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 64512:111:172.31.20.0/24 *[BGP/170] 00:01:05, MED 1, localpref 100, from 192.168.1.10 AS path: I, validation-state: unverified > to 10.8.9.9 via ge-0/0/0.0, Push 38 [BGP/170] 00:01:17, MED 1, localpref 100, from 192.168.1.5 AS path: I, validation-state: unverified > to 10.8.9.9 via ge-0/0/0.0, Push 32 to 10.3.8.3 via ge-0/0/3.0, Push 32
R8 has two entries for this prefix – one from R5, and one from R10. Can you work out what’s going on here?
Remember the default behavior of BGP. R8 is able to accept this prefix from R5, and from R10. They both use the same route distinguisher, which means that these two prefixes look exactly alike. The fact that they’re from different routers means that R8 is able to accept both of them. However, it can only choose one as best – and it’s only the one “best” prefix that the route reflector will re-advertise to the other routers in the network.
This is exactly what R8 is doing. R8 decided that R10’s prefix was the best. Therefore, this is the one and only version of this prefix that R8 is reflecting.
There are two consequences to this.
- The first is that if R10 goes down, there’ll be a delay while R8 removes its best entry, decides R5 is the best path, and advertises that new path around the network. In this test lab, that will happen in the blink of an eye. But scale this out to hundreds of customers and millions of prefixes, and the delay could become catastrophic!
- The second is that R6 no longer has the opportunity to load-balance between R10 and R5, because it’s only learning R10’s prefix. It doesn’t even know that R5’s version of the prefix exists!
Let’s think about this from R1’s perspective now. if R1 had received both prefixes, it would have decided that R5’s advertisement is the best, because R5 is metrically closer to R1. However, R1 will only receive R10’s prefix, because this is what the route reflector decided was best.
TYPE 1 ROUTE DISTINGUISHERS
This is where the other kind of route distinguisher comes in.
Instead of using your autonomous system number in the RD, you can use the loopback IP of the advertising PE. From the point of view of R5, the resulting prefix would look something like this:
192.168.1.5:111:172.31.20.0/24
Remember that the 111 in there has absolutely no meaning. It’s just a number I made up.
In fact, it’s pretty tedious to keep track of all these random numbers. That’s where Junos gives you an advantage if you choose to use this Type 1 RD. If you add the configuration below to your PEs, then Junos will just choose a random number for you! It creates a Type 1 RD on the fly. It takes whatever IP address you put in this configuration, and combines it with a random number that you don’t need to ever look at, think about, or care about.
[edit] root@R5# set routing-options route-distinguisher-id 192.168.1.5
If you add that config, then you don’t need to manually configure route distinguishers on each VPN. This makes your admin way easier, and potentially removes hundreds of lines from your configs.
For the time being I’m going to carry on configuring it explicitly within the VRF.
On all four PEs I’ve reconfigured this customer’s VPN to use these Type 1 RDs. So for example, this configuration has been added to R5:
[edit] root@R5# set routing-instances VPN_A route-distinguisher 192.168.1.5:111
Similar config is added to R1, R6, and R10.
All of a sudden, things change on the route reflector, because R8 now sees the following two prefixes from R5 and R10:
192.168.1.5:111:172.31.20.0/24 192.168.1.10:111:172.31.20.0/24
The route reflector sees them as “different” prefixes, and therefore doesn’t have to choose between them. Instead, it reflects both of them.
We can verify this on R6, who confirms that R8 has reflected both R5 and R10’s versions of the 172.31.20.0/24 prefix.
root@R6> show route 172.31.20.0/24 exact VPN_A.inet.0: 18 destinations, 22 routes (18 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.31.20.0/24 *[BGP/170] 00:00:03, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10 [BGP/170] 00:00:08, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5 bgp.l3vpn.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 192.168.1.5:111:172.31.20.0/24 *[BGP/170] 00:00:08, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5 192.168.1.10:111:172.31.20.0/24 *[BGP/170] 00:00:03, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10
Upon installing these into the bgp.l3vpn.0 table, R6 processes each of those two prefixes independently. It sees that they both have a matching route target, and so it strips the RD, and imports the remaining 172.31.20.0/24 into the VRF.
Once they’re in the VRF then it’s totally fine that they’re the “same” prefix, because they’re just two versions of the same route for the same customer, with different BGP protocol next-hops. The only point of the route distinguisher is to distinguish between the same prefix between different customers, while VPN-IPv4 prefixes are being advertised between PEs.
Now, if R10 disappears, R6 is once again immediately able to use the advertisement from R5. No need to wait! The advantage of using Type 1s is immediately clear.
But it doesn’t stop there. Using Type 1s gives you an extra advantage.
TYPE 1 RDs AND LOAD BALANCING
When a CE is multihomed, like Site B is to R5 and R10, this means that remote PEs have the opportunity to load balance between them.
Before we look at how that works, we need to enable load-balancing in general on R1 and R6.
You do this by making a policy with no match conditions (which means “match everything”). As for the action… well, you may know that in modern Junos (21.4 onwards) your policy uses an action of “load-balance per-flow”. You then apply this policy to the forwarding table, as an export policy.
In other words, these two lines of configuration are what you use to enable load balancing:
[edit] root@R6# set policy-options policy-statement LOAD_BALANCE then load-balance per-flow [edit] root@R6# set routing-options forwarding-table export LOAD_BALANCE
HOWEVER.
You may also know that in Junos 21.3 and earlier, the action in the policy is actually “load-balance per-packet”, even though this configuration ACTUALLY enables load-balancing that works in a per-flow manner. It’s a long and confusing and silly story, and one for another day. In any case, on “older” Junos, use this in your policy instead:
[edit] root@R6# set policy-options policy-statement LOAD_BALANCE then load-balance per-packet
Okay, with that out of the way, we know that R6 has received 172.31.20.0/24 for this VPN from both R5 and R10. Both of these prefixes have the same local preference, the same AS-path length, the same origin, and the same MED. They’re also both from internal BGP.
You may remember that the next tie-breaker is the smallest IGP metric to the BGP protocol next-hop. In a situation where R5 and R10 appear to a remote PE as being equal-cost, the remote PE has the ability to load-balance between them. To show you what this looks like, I’m going to change the metrics on two of R6’s RSVP LSPs to be equal:
[edit] root@R6# set protocols mpls label-switched-path R6_TO_R5 metric 1000 [edit] root@R6# set protocols mpls label-switched-path R6_TO_R10 metric 1000
Fun fact: if you’re using LDP in your lab, then R6 will immediately see them both as equal cost, because in Junos, all LDP label-switched paths have a metric of 1 by default.
Right. With that out of the way, you’re ready to enable multipath.
You might know about BGP multipath already: when everything up to and including the IGP metric is equal, you can get BGP to accept multiple prefixes, and load-balance between them. For MPLS Layer 3 VPNs you enable this within the VRF itself, which makes sense because some customers might not want it.
Adding it to a particular VPN is as simple as this:
[edit] root@R6# set routing-instances VPN_A routing-options multipath
And with that, the results of R6’s entry for this prefix changes somewhat. Notice below that there’s now a “Multipath” entry in this VRF, and the distinction of an entry for “routing use” and an entry for “forwarding use”. What’s going on here?
root@R6> show route 172.31.20.0/24 exact VPN_A.inet.0: 18 destinations, 27 routes (18 active, 0 holddown, 0 hidden) @ = Routing Use Only, # = Forwarding Use Only + = Active Route, - = Last Active, * = Both 172.31.20.0/24 @[BGP/170] 00:00:09, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5 [BGP/170] 00:00:09, MED 1, localpref 100, from 192.168.1.8 AS path: I, validation-state: unverified > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10 #[Multipath/255] 00:00:09, metric 1, metric2 1000 > to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R5 to 10.6.7.7 via ge-0/0/0.0, label-switched-path R6_TO_R10
The Multipath entry has a # sign next to it, which you can see from the index means that this is for “forwarding use only”. The fact that this entry is for “forwarding use” tells you that R6 is now going to use both the LSP to R5 and the LSP to R10 for forwarding. In the data plane, traffic is load balanced.
However, of the two prefixes R6 is learning from R5 and R10, R6 can only re-advertise one of them to any directly-attached CEs. Remember that by default, BGP chooses only one prefix to re-advertise. Indeed, you saw exactly this behavior with the route reflector earlier.
This is what the “routing use only” section is about. R6 has chosen R5’s advertisement as the “best” prefix. Why? Because so many of R5 and R10’s BGP attributes were the same, that R6 had to go down to the bottom half of the BGP path selection process, where you’ll find arbitrary tie-breakers. In this case, R5 had the lowest Router ID.
So in the control plane, R6 is re-advertising only one of these prefixes. But in the data plane, R6 is load-balancing between both of them.
And with that, we see the second advantage of Type 1 RDs. If you have configured multiple PEs to advertise the same prefix with all the same BGP attributes – local preference, MED, and so on and so on – then Type 1 RDs give you the option to accept and install advertisements from multiple PEs for the same prefix, and load-balance across all of them. MmmmmMMMMM!! That’s a real nice option, don’t you think?
THAT’S IT!
I honestly don’t know a single reason to use Type 0 or Type 2 RDs. Wherever possible I would recommend using Type 1, and I’d also recommend using the config I showed you that just automatically generates them. There’s a temptation to manually configure an RD that looks similar to the route target, but there’s no particular advantage there. Much nicer to just let your PE generate it randomly, and have a happy life.
Hey there: thanks for reading my post! If you enjoyed it, I would be delighted it you shared it on your favourite social media platform of choice, whether it be MySpace, Friends Reunited, Bebo, GeoCities, or the Anime Web Turnpike.
If you’re on Mastodon, follow me to find out when I make new posts. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.
Thanks for reading! See you next time!


