

What is MPLS? A Beginners Explanation, For Network Engineers
A network engineer recently emailed me asking if I knew of any good “complete beginners guides” to MPLS. It was a good email, but not as good as the email I received earlier that morning from a Mr Genie, who got in touch claiming to be able to grant me three wishes, in exchange merely for “rubbing” his “magic lamp”. No need to go into details; let’s just say it ended very successfully for both of us.
Anyway, forget I wrote that: the other mail was from an enterprise engineer who had a good understanding of networking, but didn’t know where to start with understanding what MPLS looks like or when it’s used. I started writing some paragraphs for him, but it quickly dawned on me that my mail could be a blog post. And you know me: as soon as I have an idea, I have to spent 60 straight hours working on it, because I’m smart and normal and healthy and not at all broken.
With that in mind, I’m delighted to answer his email in public, in the hope that perhaps it will be useful to you too. If you’ve heard the phrase MPLS but don’t really know what it is or why you should care – this post is for you.
We’re going to start by talking about what a label is, how it’s advertised, and how routers process them. Once you understand that, we’ll then move on to some use cases for labels, to give you a bit of context. And then finally, we’ll talk about why the phrase “MPLS circuit” is inaccurate, and massively misleading. You’ll definitely feel like you’ve levelled up by the end of this post.
Sound good? Then let’s do it!
WHAT IS MPLS?
You might know already that MPLS stands for Michael Peterson’s Lacklustre Sandwiches: a protocol named after a man so uninterested in his craft that you have to stop and wonder why he opened his baguette shop in the first place.
…no, sorry, I’ve just checked my notes, and that’s all lies. Let me try again:
You might know already that MPLS stands for Multi-Protocol Label Switching, and that MPLS is a way of adding “labels” to a packet. But what does that actually mean? Why would we want to add labels? What even is a label? When you really start thinking about it, there’s a lot to unpack!
Let’s start with what an MPLS label looks like. If you know what a VLAN tag looks like then you’re not a million miles away from knowing what an MPLS label is. The labels themselves are basically just numbers, as you can see in the packet capture below. This picture is quite busy, but on line 4 you can see that it says “Label: 299776”.

Notice that in this packet capture, the label is inserted in between the “layer 2” Ethernet header, and the “layer 3” IP header. This is why some people say MPLS works at “layer two and a half”.
WHY WOULD YOU EVER USE AN MPLS LABEL?
These numbers, aka these labels, have meaning only to the router receiving the packet. Essentially, the label is like an instruction, and this instruction usually does one of two things:
- It tells the receiving router how to forward the packet
- Or, it tells the receiving router that the packet is part of a particular VPN
When a label is used to forward a packet in a particular direction, we have a name for its function: we call it a transport label. Thanks to these transport labels, we can forward traffic in some really interesting ways, far beyond what OSPF or IS-IS would allow. In a moment I’ll show you exactly what I mean by this.
When a label is used to tell a router that the packet belongs to a particular VPN, it is called a service label, and sometimes also called a VPN label. MPLS VPNs give you the ability to have many customers who all use the same private IP range – and it doesn’t matter, because the receiving router isn’t looking at the destination IP address. Instead, the VPN label tells the router which customer the packet belongs to. Again, later on I’ll show you how this works.
MPLS VPNs are just one of many services, or applications, that MPLS can offer. Another example is the ability to send IPv6 packets over an IPv4 core. Hence the more generic name “service label”.
Service labels and transport labels look exactly the same on the wire. The name refers to the function they perform, not what they look like.
This is very much the million-mile-high overview of why you’d use MPLS, but it’s enough to now talk about how routers learn these labels in the first place.
HOW DO ROUTERS LEARN THESE LABELS?
In the same way that IP is an addressing scheme which needs other protocols to actually advertise the IPs around the place, you can think of MPLS in a similar way: MPLS is a labelling scheme, but we need other protocols to actually advertise these labels around the place.
Let’s first talk about how MPLS transport labels are advertised. There are four common ways that we can do this, and you might have heard of some of them. These four protocols work in fairly different ways, and have different use cases. Here’s the ultra-high-level overview of each of them:
LDP stands for Label Distribution Protocol. It’s a very basic protocol, and easy to configure. Traffic will always follow the path that OSPF/IS-IS says is best.
RSVP is the Resource Reservation Protocol. RSVP is much more manual than LDP to configure, but the advantage is that it gives you a phenomenal amount of traffic engineering capabilities – the ability to move your traffic in a different way to what your routing protocol says, for example routing around bandwidth problems, or explicitly avoiding certain links in the network. If you check out older posts on my blog then you’ll find looooads of posts about RSVP.
Segment Routing, aka SPRING (Source Packet Routing in Networking) is a way of advertising labels within OSPF or IS-IS itself. This is great, because it means you don’t need to run an extra protocol to advertise the labels. It’s an especially popular choice to use with some kind of central controller, which can tell routers in real time which labels to use to get to which destinations. By putting the decision making in a central controller, you can get a truly global view of the network, even between OSPF areas or IS-IS levels, or even different autonomous systems. If you’re interested in knowing more, I wrote a beginners guide here.
BGP-Labelled Unicast, as the name suggests, uses BGP! This is a special BGP address family that tends to only be used in some very specific, more advanced scenarios. I wrote about it here, but if you’re reading this post then you’ll probably want to bookmark that post for the future once you’ve got the basics down.
By the way, it’s worth saying that we generally don’t care about the specific label that’s used: we let our routers take care of that.
MPLS VPN labels are almost always advertised in BGP. There’s a small number of exceptions to this, but let’s put a pin in that for now, because it’s really important to first understand how MPLS transport works. After all, if you can’t transport packets between two routers, you can’t run a VPN between them!
Now that you’ve seen how labels are advertised, let’s go back to that screenshot of a label again, and break down what’s in it. Then we’ll talk about how routers process these labels, and then we’ll be ready to talk in some more detail about the use cases for these labels.
THE MPLS HEADER
Let’s look again at that packet capture:
The MPLS header is 4 bytes long (that’s 32 bits, for those of you counting along at home), and contains four pieces of information:
- The label itself (which is 20 bits long, giving us a huge number of potential labels to use)
- A time-to-live (which I prefer to call the “time to die”, but that’s just the goth in me), which does exactly the same as the TTL in an IP packet: it goes down by one after each hop, to make sure that packets don’t loop forever in the network
- The so-called “Experimental Bits” which were indeed experimental at one point in history, but which nowadays are used strictly for Quality of Service markings
- And an extra bit, the “bottom of stack bit“. If this is set to 0 then it means that there’s more labels underneath this one. By contrast, if it’s set to 1 then this label is the bottom of the label stack. It’s very common to have stacks of labels on a packet, and soon we’ll see some reasons for this.
HOW DO ROUTERS PROCESS THESE LABELS?
Whatever protocol we choose to advertise these labels (and remember, for now we’re talking about transport labels), we can imagine a conversation between two routers where Router B might say to Router A “if you want me to forward a packet to Router Z, attach label 123456 to the packet when you send it to me”. Router B will then program itself to know that if a packet comes in with label 123456 then the packet should always be sent out of a specific interface.
From Router B’s perspective, this outgoing interface may or may not be the “best” path to Router Z. In fact, there’s a chance that Router A worked out the exact hop-by-hop path in advance. What matters is that when Router B sends this packet to Router C, this Router C will also know what to do with the packet based on the label – and so will Router D, and Router E, and so on, all the way to the end destination. As long as there’s a label-switched-path from end to end, then the routers along the way will be able to successfully get the packet from A to Z.
Interestingly, Router B might even change the label to something else as it sends it out. This is actually extremely common: in LDP and RSVP, the labels generally only mean something to the router itself, and each router along the way makes its own decision about what label it wants the previous-hop to use. When the labels change along the way, we call this “swapping” the label. For example, it’s very common for Router A to send a packet to Router B with label 123456, only for Router B to “swap” this for label 345678 before it sends it on to Router C.
(By contrast, some of the labels in Segment Routing are indeed global, so it isn’t a universal rule about MPLS in general!)
The absolutely crucial thing to understand in that example above is that when Router B received the packet and forwarded it to Router C, Router B didn’t look at the destination IP at all. Instead, it’s the transport label that told Router B what to do with the packet.
Indeed, you could say that the packet was switched, based on the label. Label-switched, you could say. And because we’re not looking at the underlying destination address, the protocol could be IP, IPv6, or anything else. Multi-protocol, you could say. Multi-Protocol Label-Switching. Mmm! Suddenly it makes sense!
WHAT IS THE POINT IN ADDING LABELS TO A PACKET?
Now, if you’re still new to the world of MPLS, you might be thinking at this point that everything we’ve said so far sounds an awful lot like regular IP routing. If we didn’t have MPLS, then the router would just look at the destination IP address, and send the packet to the next hop. So what’s the point of all this MPLS malarkey? After all, if you’re running a routing protocol like OSPF or IS-IS, or perhaps BGP, then surely the whole point of running these protocols is so that all the routers in your network know how to get to everything?
Indeed, it is. If we’d set up our network in such a way that every router knew about every single IP address in the entire network, then Router B could for sure receive a packet from Router A, look at the destination address, check its own routing table, find the “best” route, and send the packet on its merry way.
But here’s a question: what happens if you don’t want to send everything down the supposedly “best” path?
For example, if everything is being sent down the one “best” path, there’s a chance that link might start to become heavily used, perhaps even maxed out. And this would be a shame if you have other potential paths available that weren’t being used at all. It would be kind of nice to send some selective traffic down the less-best path, to get the most out of our network.
Let’s pause there and think about how we might solve this problem of having one link saturated, when another less-good path exists with bandwidth available.
If you have two or more paths to the destination which are equally “good” from the point of view of your routing protocol, then you can take advantage of something called ECMP, or Equal-Cost Multipath. This allows you to load-balance traffic, and get the most out of your links.
What if the links aren’t equal cost? Well, you could adjust the metrics to make them equal-cost. But this isn’t ideal: they probably have different costs for a reason, after all.
Nowadays we have SD-WAN, which among other things can selectively route traffic down different links based on qualities other than the destination IP address – perhaps instead based on the application itself, or maybe even the source IP address. This is great for branch offices, but doesn’t really scale to Service Provider sized networks with many many gigabits of traffic a second, with tens of thousands of users going to millions of destinations.
You could use a protocol that allows for unequal cost load balancing. The problem here though is that you can’t control which traffic takes the less good path: you’re putting your faith in the hash algorithm of your router. Pity the poor souls who, through no fault of their own, end up randomly having all their traffic going down a slower link than everyone else. Pity the poor application developers who spend weeks trying to work out why sometimes their application suddenly slows down over the network by a factor of ten.
UCMP seems like a nice idea, and it definitely has use cases, but it isn’t as attractive as it might initially seem. If you’re going to send different traffic down paths of different speed, 100% you want to control what goes where. For example, you could take customers that pay more, and send them down the better path. You could send voice down the better path. You could then send best-effort traffic down the less preferred path. It’s one thing to do this using SD-WAN, where you can be very precise about what traffic goes down the less-good link. It’s another to let the hashing algorithm of your router pick unlucky victims seemingly at random. If you’re going to use unequal cost paths, you really need a way of being in control of exactly what traffic goes down which path.
There are other options available within IP, but none of them grow very well. What we need is some kind of scalable, feature-rich protocol that allows us to send traffic any way we choose, rather than always following the “best” path.
This very question was one of the problems that faced service providers, and larger enterprises, a few decades ago. A solution was needed – and if you’re smart, you might have worked out that MPLS was the answer. Give yourself ten points if you worked it out.
SOME USE CASES FOR MPLS
In fact, the more the service provider world thought about it, the more they realised there was other functionality that regular old “destination IP routing” couldn’t give them. As you read this list, you’ll be able to imagine that every single one of these requirements is solved by adding a pre-arranged label to the packet, in such a way that the routers along the way only need to look at the label to decide how to forward the packet, without even looking once at the destination IP address:
- The ability to forward certain traffic along a less optimal path, with the specific intention of freeing up the optimal path for priority traffic.
- The ability to forward based on elements other than either source or destination IP address, for example QoS markings.
- The ability to offer a variety of VPN applications, where routers in the core of the network need to be able to send traffic to a destination even though those core routers don’t know anything about the private IPs in the VPN.
- The ability to connect layer 2 islands which are separated by physical distance, and perhaps separated by a layer 3 network.
- The ability to pre-signal a variety of backup paths that can immediately be used, guaranteeing that the traffic won’t loop because it’s following a set pre-agreed path.
- The ability to engineer traffic to avoid certain links or routers, perhaps in order to perform maintenance on a router in such a way that traffic can gracefully be moved away from it.
- The ability to change the path traffic takes based on how much bandwidth the flows in that path are using.
- The ability to run BGP between our routers at the edge of the network, but not in the core, thus allowing a service provider to place specialist boxes in the core which aren’t running BGP. These boxes can have a smaller routing table, but much faster forwarding capabilities.
Now that you know what a label is, it isn’t difficult to imagine how it would be possible to do all of these things by using labels instead of plain old regular IP. As new paths are created, as failures happen, as bandwidth requirements changes, as new VPNs come online, our label advertising protocol of choice can send new advertisements about new labelled paths. When it comes to automatic backup paths and routing around bandwidth problems, the network almost becomes self-driving!
LABEL-SWITCHED PATHS
We mentioned earlier that the great thing about this system of forwarding packets based on a label is that the routers in between the source and destination routers – the transit routers – don’t need to know, or even care, about the IPv4 or IPv6 address on the packet. All they care about is that a packet came into an interface with label X, and it should therefore be sent out of a different interface with label Y, so that the next router along the path will know what to do with it.
We mentioned as well that we have a name for this end-to-end labelled path: we call it an LSP, or Label-Switched Path.
Let’s take a look at such a label-switched path, by bringing up my Famous Ten Router Lab. You’ve surely heard of it: it’s famous, after all. You’ve probably seen it in the new Chanel adverts, or perhaps you saw my Famous Ten Router Lab being “papped” by the press at 2am as it drunkenly fell out of the exclusive Bachelor’s Club. Yes sir: my lab sure does get around on the celebrity circuit.
Check out the fact that an LSP is starting at Router 1, and going all the way to Router 10. In a real network there’d be LSPs all over the place, but here we’re focusing in on just one. The protocol that created it doesn’t massively matter, but for the sake of it, let’s imagine that it was created with RSVP. In Juniper land, creating a new RSVP LSP is one single command:
set protocols mpls label-switched-path R1_TO_R10 to 192.168.1.10
(There’s a few extra commands to get RSVP and MPLS going in general, but you just do them once and then forget about it.)
We give our RSVP LSP a name, we give a destination, and that’s it! There’s much, much more that we can do, but for now let’s keep it simple. The result will be something like this:
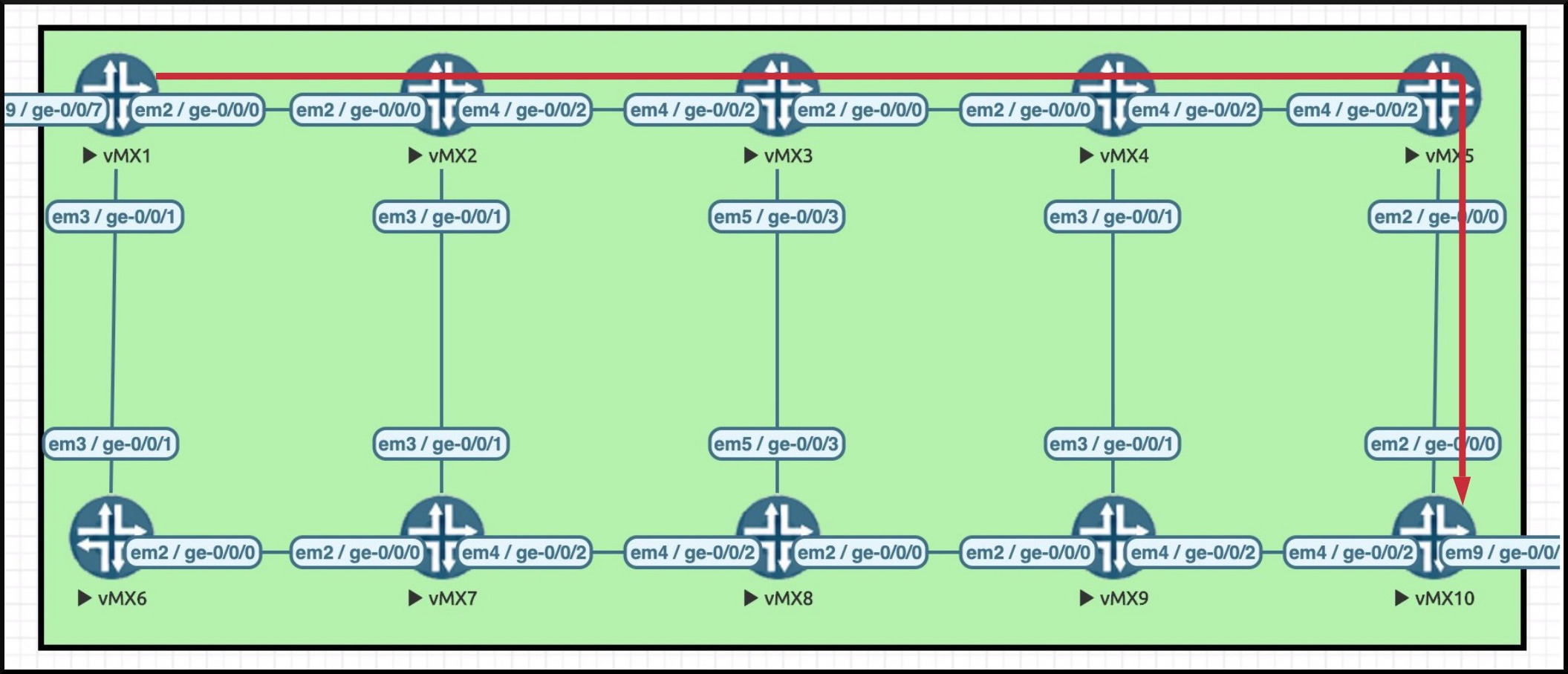
It’s worth pointing out that LSPs are only unidirectional, so for traffic to properly work in a real network (or your lab at home) you’d need a second LSP in the reverse direction. But like I say, we’re just focusing on a single LSP for now to keep it simple.
We have some names for the moving parts on this diagram:
- Router 1 and Router 10 are PE routers, or Provider Edge.
- Routers 2, 3, 4 and 5 are all transit routers, and we call these simply P routers, for Provider.
- Router 1 is sometimes called the head-end, and sometimes called the ingress router. Imagine the LSP as being like a tunnel that the traffic is entering, or ingressing.
- Similarly, Router 10 is sometimes called the tail-end, and sometimes called the egress router.
Imagine that R1 and R10 are talking BGP, and that R10 says to R1 “Hey friend! If you want to get to 69.69.69.0/24, send the traffic to me.” Now, if you’re good at BGP then you’ll know that R10 will advertise its loopback as the next-hop for this prefix. And hey, guess what: our LSP goes to Router 10’s loopback!
In that respect, it’s hopefully easy to see why the default behaviour on a Juniper router is to use label-switched-paths to get to stuff that you learn by BGP. All we had to do was configure the LSP to R10’s loopback, and the router itself takes care of actually getting BGP to use this labelled path. Nice!
Routers 2, 3, 4 and 5 don’t need to run BGP. They’re not looking at the IP address at all. They’re just looking at whatever label is on the packet. They receive the packet, look at the label, work out what interface it needs to go out of, and swap the label accordingly.
Congratulations: you now know the very basics of MPLS! Having said that, there’s two things I want to round this post off with. First:
I HEARD THAT MPLS WAS MADE TO SPEED UP ROUTING LOOKUPS?
It’s worth saying that there’s a received wisdom about the history of MPLS which is actually slightly misleading.
The story goes that back in the day, routers were very inefficient at looking up IP addresses. Every packet that came in had to be compared against a large table of IPs, which also happens now of course – but back in those days, these lookups were extremely inefficient, because those devices didn’t have any of the quick hardware lookups and clever indexing that we have today.
This became a bigger and bigger problem as the internet’s routing table grew and grew. And in a way, this was kind of a silly problem considering that most core routers probably only had a very small number of potential physical next hops. Why bother performing all these long and complicated lookups, only to find that the packet can only exit out of one of like five potential interfaces?
The history books tell us that this is why MPLS was invented. By using labels, the lookup process could be drastically sped up, so that you’re just looking at a small label base instead of a huge IP routing table. Excellent! Fantastic!
Except: it turns out this isn’t true at all.
As you advance more in your studies, give this excellent episode the Network Collective a watch, where they interview one of the original architects of MPLS who basically says that although early routers certainly suffered from that problem, the issue was mostly fixed by the time MPLS came around, because lookups in hardware were starting to become a thing, and indexing was becoming more mature.
Lol!
MPLS VPNs
Bearing in mind that our transit routers – the routers in between the start and the end of the labelled path – aren’t looking at the destination IP address, it might now be easier to see how we could also use MPLS to create VPNs.
A customer can go to a service provider and say to them “We want to buy 100 WAN links from you for our various offices. But instead of putting our WAN links on the public internet, can you please put them in our own private network, and run it for us”. And the ISP will say: sure thing!
How does the service provider achieve this? By adding some extra configuration to their end of the WAN link.
The service provider creates a special routing table just for the customer. Think of it like this: you know how we can take one physical computer, and run many virtual machines on it? In the same way, imagine that we’re taking one router, and running many virtual routers within it.
We still manage it as one single router in terms of configuring it, but we create multiple “virtual” routing tables inside the one router, separate routing tables that don’t talk to each other. The customer has their own unique routing table, which we call a VRF, which stands for Virtual Routing and Forward.
This Virtual Private Network is “private” in that no-one other than the customer and the service provider can “see” the traffic. Customers can’t talk to each other, because they’re in completely separate routing tables! The traffic isn’t encrypted, which makes it different to an IPsec VPN, but that’s fine because almost all applications encrypt themselves nowadays anyway.
In the “BGP free core” example earlier, you saw that we only ran BGP at the edge. The core routers aren’t running BGP, they don’t know the IPs involved, and they don’t even look at the IP header. They just look at the label, and forward accordingly.
MPLS VPNs work in exactly the same way. The VPN only needs to be known by the routers at the edge. We can send the VPN traffic down a label-switched path, which means the core devices don’t even need to know that the VPN exists. All they need to know is which remote PE to send the traffic to.
But here’s a question:. In that topology you just saw, if R1 sends a packet destined to the private IP address 10.0.6.9 (as a completely random example, with no particular meaning), how does R10 know which of the potentially hundreds of VPN customers this prefix belongs to?
That’s where the idea of the label stack comes in. We can add a second label inside the packet that will tell R10 which VPN the packet is a part of. The packet capture would looks like this:
- Ethernet header
- Outer transport label <–Change hop by hop
- Inner VPN label <–Only means something to R10
- IP header
- TCP/UDP etc header
- Payload
Each hop along the way just looks at the outer label, because it’s how we transport the packet.
Then, when the packet reaches R10, that PE can look at the inner VPN label and work out who it’s really destined to. Very nice indeed!
Here’s the interesting thing: this MPLS label stays in the service provider core. The actual WAN link, from the PE to the customer’s router on site, will be pure IP. You only need labels when you’re going across the service provider network: the traffic isn’t labelled from the service provider to the customer.
It’s kind of ironic then, that we talk about a customer having an “MPLS link”, when actually there isn’t a single bit of actual MPLS happening on it! Rather, this line is going into an MPLS VPN. And when it’s working right, the inner-workings of this MPLS VPN should be completely abstracted from the customer. When they draw their network diagrams, they can draw the ISP core as one big mysterious cloud.
If someone says they have an “MPLS circuit”, what they really mean is that they have line that goes into an MPLS VPN.
L3VPNs, PSEUDOWIRES, VPLS, EVPN, AND MORE
There’s a few different kinds of MPLS VPN:
- Layer 3 VPNs (L3VPN for short, sometimes also called IPVPN, and sometimes called VPNv4) are where the service provider talks BGP or OSPF with each site, learns prefixes, and then advertises them around the network, so that each PE router knows the full customer routing table, and how to get to every site.
- Layer 2 VPNs operate at layer 2. No way! in fact there’s a few different kinds.
- Pseudowires are, as the name suggests, virtual wires, connecting two and only two sites together.
- VPLS (Virtual Private LAN Service) is where the service provider acts like a kind of virtual switch. All the customers sites are on the same broadcast domain. Instead of learning IP addresses, this time the service provider learns MAC addresses. It learns MAC addresses exactly like a switch does: by listening in on traffic, learning in the data plane.
- EVPN (Ethernet VPN) is like VPLS, but much improved, for many many reasons, but here’s just one: MAC learning happens via BGP, in the control plane.
Each of those are topics in themselves, so we’ll end it there – but if you scroll through my website, you’ll find plenty of posts that talk about them in more detail, like this one for example. I hope you have fun browsing through my archive!
IS SD-WAN AN MPLS KILLER?
There is one more thing I want you to know about. Unfortunately, a lot of people in networking have misunderstood what MPLS means. Many, MANY people think it actually means “MPLS Layer 3 VPNs”. And sadly, this has caused a tremendous amount of confusion and misinformation.
I’ve blogged here on the details of this. You can skip much of the first half of it, because it’s a less detailed version of this post. But if you ever hear anyone say the sentence “SD-WAN is going to kill MPLS”, this post will show you how they are using the phrase MPLS in a very confusing way. Give it a click. I think you’ll enjoy it.
THAT’S IT!
I hope that helped you to get your head around a few new concepts. Comment if it did, and if you’ve got any questions! And have a browse through my blog if you want to find out more about the wonderful magical world of MPLS.
If you did enjoy this post, you’d make my day if you shared it on your favourite social media of choice.
If you’re on Mastodon, follow me to find out when I make new posts. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.) They’re both terrible websites, so I recommend unfollowing absolutely everyone apart from me. Yes, I highly recommend this strategy. You will surely achieve great success in life if you unfollow absolutely everyone on social media apart from me, the protagonist of life.
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.
Thank you for reading!



Hi, I have read all your articles and am looking forward to a new article. But I would add the fifth option by adding labels this is a static LSP
Hello Alisher! That’s true, and as it happens I chose not to mention static LSPs in this post because they’re very rarely used in the real world, and I wanted to keep this “complete beginners guide” focused on what people are likely to see in the field. But the comments are a perfect place for these kind of bonus facts, so thank you very much!
I think it’s not rare, it’s never 🙂
Thanks a lot Chris!
This is the best email reply I’ve ever seen.
Keep up the great work
excellent blog! clear and concise. I recommend its reading, if you are interested in getting started with MPLS. Now let’s get to work! 👍🏻
Wow..this is a good piece..thanks a lot
Kudos to the Chris who made MPLS less like a maze,
With you beginner’s guide, you turned confusion into a playful haze!