

INTERPROVIDER OPTION C, ON JUNIPER JUNOS ROUTERS – PART 3: USING RSVP, AND PUTTING BGP-LU INTO INET.0
There’s been a lot of incredible Part 3’s in history. To name just a few: Back To The Future, Part 3. Alvin and the Chipmunks: Chipwrecked. And of course, the greatest movie in all of cinema history, Shawshank Redemption Part 3: Tokyo Drift.
With that in mind, it’s a true honour for this blog post to be listed (by me) alongside the greatest trilogies of all time, as we embark on the third and final part of this series on using Interprovider Option C to extend MPLS VPNs between two ISPs.
In Part 1 we learned how to do a basic config, and in Part 2 we looked at the actual use case for Option C, as well as taking a detailed look at how the labels work end-to-end. To keep things simple, we ran LDP everywhere, and we also put all our BGP-Labeled Unicast routes into inet.3.
In this third and final post, we’re going to learn some things to be aware of in different configurations. In particular, we’re going to turn on RSVP in ISP 2, and we’re going to put our BGP-LU prefixes in inet.0. We’ll see how it breaks our setup, and then we’ll look at the configuration we need to get it working again.
Then afterwards, when we’re all done… we could go for a meal maybe? Or just a drink? Or we could go catch a movie? …what? You’re busy? Oh okay, no worries, never mind. No it’s cool, it was only an idea anyway, I don’t mind. No worries! No worries.
RECONFIGURING ISP 2 – TURNING ON RSVP
Let’s remind ourselves of our topology. As always, I recommend opening this pic up in a new tab, as we’re going to be referring back to it a lot:
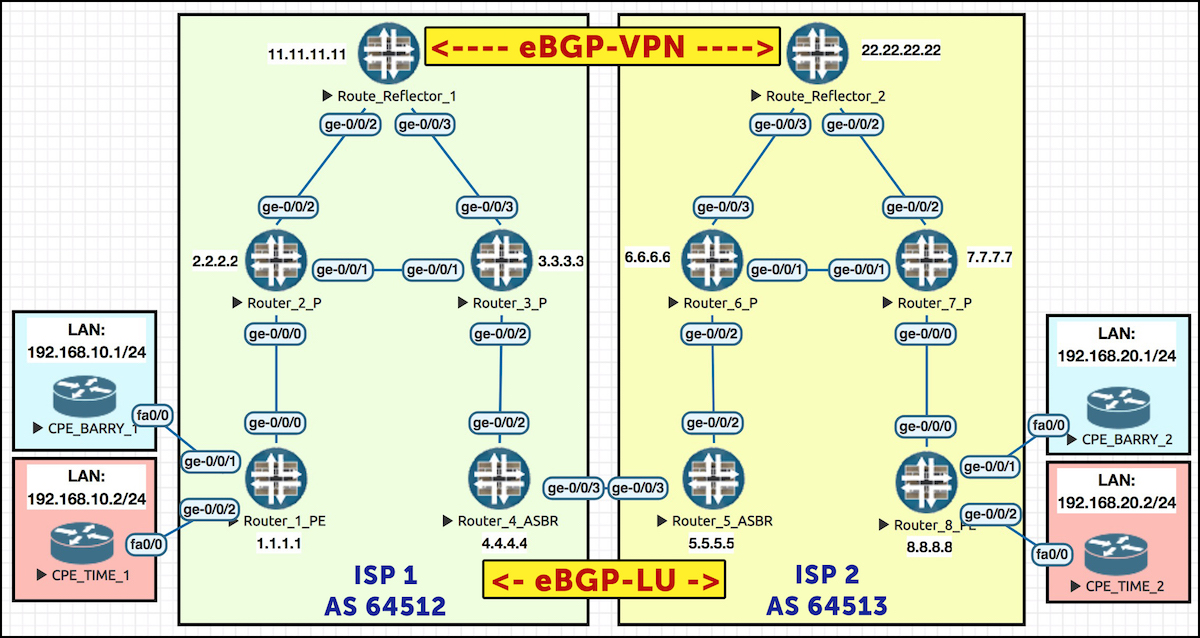
First, let’s remove all LDP config from ISP 2. We add this line to all routers in ISP 2:
delete protocols ldp
Next, I’m going to turn on RSVP, and create two label-switched paths. On Router 5, I’m making a path to Router 8. And on Router 8, I’m making a path back to Router 5. Here’s some new config on Router 5:
set protocols rsvp interface ge-0/0/2.0 set protocols mpls label-switched-path PE5_to_PE8 to 8.8.8.8 set protocols mpls label-switched-path PE5-to-RR2 to 22.22.22.22 set protocols ospf traffic-engineering
The last line is important: in IS-IS, the traffic-engineering extensions for RSVP are turned on by default in Junos, so RSVP’s Constrained Shortest Path First (CSPF) algorithm can run with no problems. In OSPF, we need to add that command to every router in ISP 2.
We add the equivalent config on Router 8. We also turn on RSVP and MPLS on the relevant infrastructure interfaces on Routers 6 and 7. Notice that I haven’t turned on RSVP on ISP 2’s route reflector, Reflector 2.
Now, in previous posts on this blog we’ve talked about how it’s common to not turn on MPLS on your route reflectors, when your route reflectors aren’t also acting as transit routers. After all, why do they need label-switched paths to routers that they’re not sending ingress or transit label-switched traffic to? All the route reflector is doing is reflecting prefixes.
With that in mind, in the past we’ve used some commands to make the router *think* it can successfully resolve the next-hop of VPN prefixes, just to trick it into actually reflecting the prefixes. In this story though, things are a little bit different.
Imagine we turn on RSVP everywhere apart from our route reflector. Now, remember that ISP 2 has learned about 11.11.11.11, ISP 1’s route reflector, via BGP Labeled-Unicast. With that in mind, does the BGP peering between the two reflectors come up?
root@Reflector2> show bgp summary | match 11.11.11.11 11.11.11.11 64512 24 37 0 2 4:24 Active
Nope! How come? We still have a route to 11.11.11.11, don’t we?
root@Reflector2> show route 11.11.11.11 root@Reflector2>
Aah! That’s interesting. So we had a route when we were talking LDP everywhere, but not when we’re only talking RSVP between our PEs, and any router in between. Let’s see if the route is being learned and ignored.
root@Reflector2> show route receive-protocol bgp 5.5.5.5 11.11.11.11 hidden extensive inet.0: 14 destinations, 14 routes (13 active, 0 holddown, 1 hidden) 11.11.11.11/32 (1 entry, 0 announced) Accepted Route Label: 299872 Nexthop: 5.5.5.5 MED: 1 Localpref: 100 AS path: 64512 I {snip}
(A note about this output: you’ll remember that we added a policy on our route reflector to copy our 11.11.11.11 BGP-LU route from inet.3 into inet.0. When typing the command above, and the ones below, we also get identical output for the inet.3 table. I’ve removed it to keep the post short.)
Now that IS odd. It’s hidden – and yet, it’s saying that it’s “accepted”! Not particularly helpful. Perhaps our routing table will tell us more?
root@Reflector2> show route 11.11.11.11 hidden extensive inet.0: 14 destinations, 14 routes (13 active, 0 holddown, 1 hidden) 11.11.11.11/32 (1 entry, 0 announced) BGP Preference: 170/-101 Next hop type: Unusable {snip} Primary Routing Table inet.3 Indirect next hops: 1 Protocol next hop: 5.5.5.5 Push 299872 Indirect next hop: 0 -
Hmm. Still not very explicit. But that label is a clue.
Router 5 is telling Reflector 2 “to get to 11.11.11.11, come to me and add label 299872 to the packet” Can you see the problem? Reflector 2 needs to be able to add at least one more transport label to this packet. Otherwise, if Reflector 2 just added this one label to the packet, and passed it to the next hop (Router 6), then Router 6 would have no idea what to do with it! Label 299872 only has meaning to Router 5.
There’s another command that can help us see the problem:
root@Reflector2> show route resolution unresolved Tree Index 1 8.8.8.8:1:192.168.20.0/88 Protocol Nexthop: 8.8.8.8 Push 299840 Indirect nexthop: 2 no-forward 1.1.1.1/32 Protocol Nexthop: 5.5.5.5 Push 299856 Indirect nexthop: 0 - 11.11.11.11/32 Protocol Nexthop: 5.5.5.5 Push 299872 Indirect nexthop: 0 - {snip}
The fact that we don’t have an indirect next-hop means that we can’t resolve 5.5.5.5 in a labeled way. All we have is an unlabeled path:
root@Reflector2> show route 5.5.5.5 inet.0: 14 destinations, 14 routes (13 active, 0 holddown, 1 hidden) + = Active Route, - = Last Active, * = Both 5.5.5.5/32 *[OSPF/10] 00:15:04, metric 2 > to 10.10.226.6 via ge-0/0/3.0
All of this is a very long way of saying: if you’re doing Option C, and you’re using RSVP, it’s essential that you have label-switched paths on your route reflectors, even if the reflectors are outside of the MPLS transit path. Otherwise, they won’t be able to get to the route reflector in the other ISP.
There’s a few ways we could fix this, but because we’re in a simple lab, let’s just make RSVP LSPs between routers 5 and 8. We add this config to Reflector 2:
set protocols rsvp interface ge-0/0/2.0 set protocols rsvp interface ge-0/0/3.0 set protocols mpls label-switched-path RR2-to-PE5 to 5.5.5.5 set protocols mpls label-switched-path RR2-to-PE8 to 8.8.8.8 set protocols mpls interface ge-0/0/2.0 set protocols mpls interface ge-0/0/3.0 set protocols ospf traffic-engineering
And then:
root@Reflector2> show bgp summary | match 11.11.11.11 11.11.11.11 64512 5 5 0 2 5 Establ ---------------------- root@Reflector2> show route 11.11.11.11 inet.0: 14 destinations, 14 routes (14 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 11.11.11.11/32 *[BGP/170] 00:25:47, MED 1, localpref 100, from 5.5.5.5 AS path: 64512 I > to 10.10.226.6 via ge-0/0/3.0, label-switched-path RR2-to-PE5 ---------------------- CPE_BARRY_1>ping 192.168.20.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.20.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 116/125/148 ms CPE_BARRY_1>
Hooray!
Now everything is working again, let’s make the second big change: instead of putting my BGP-Labeled Unicast prefixes in inet.3, I’m actually going to put them in inet.0.
RECONFIGURING ISP 2 – PUTTING BGP-LU PREFIXES INTO INET.0
Now, usually we’d want BGP-LU prefixes in inet.3, because then we can use them to resolve BGP next hops. We usually leak a certain number of prefixes into inet.0 when they’re needed, just like we’ve done in this lab: on Reflector 2, we leaked 11.11.11.11 into inet.0, purely because it needs to be in inet.0 for the BGP peering to come up.
In fact, although I’ve personally only worked at a small number of ISPs, I can still tell you these two things: 1) Everywhere I’ve ever worked has decided to put BGP-LU prefixes in inet.3. 2) Everyone I’ve talked to about it has only ever put BGP-LU prefixes in inet.3. In the real world, in my experience, not a single person puts their BGP-LU prefixes in inet.0.
So then, why are we bothering to put them into inet.0 now? Two reasons.
First of all, the vast majority of other posts on the internet about Option C put them in inet.0. That includes the official Juniper knowledge base articles on Option C!! This tells me that there must at least be some people in the world who do this in production.
Secondly, there may be times when it’s actually preferable to have them in inet.0, such as if you need to use most/all the prefixes for general reachability. If you also need to use them to resolve BGP next-hops then you can then leak them the other way, into inet.3. The problem with this setup though is that you can’t run BGP unicast and BGP-labeled unicast at the same time. Well, you can, it’s just that you get a lot more labels. It’s complicated, and we talked about the different variations in my post all about BGP-LU, so give that post a read if this paragraph is news to you.
Anyway, let’s put this config on Router 5, and apply similar config throughout ISP 2, including on our route reflector:
delete protocols bgp group AS64513 family inet unicast delete protocols bgp group AS64513 family inet labeled-unicast rib inet.3 set protocols bgp group AS64513 family inet labeled-unicast delete protocols bgp group TO_AS64512 family inet labeled-unicast rib inet.3 set protocols bgp group TO_AS64512 family inet labeled-unicast
And now we’ve done that, let’s take a look at all the many fun ways that our lab is broken.
FINDING THE PROBLEMS
Now we’ve done that, let’s check that our BGP peerings are back up:
root@Reflector2> show bgp summary | match Est 5.5.5.5 64513 5 5 0 3 16 Establ 8.8.8.8 64513 33 19 0 3 16 Establ 11.11.11.11 64512 5 5 0 4 13 Establ ---------------------- root@Router5> show bgp summary | match Est 10.10.45.4 64512 13 15 0 0 4:44 Establ 22.22.22.22 64513 24 19 0 2 43 Establ
Good stuff!
Now, we know that when VPN traffic goes from R1 to R8, R1 pushes three labels onto the packet. We’ve made some changes to the MPLS in ISP 2, so Router 1 is probably using new labels now. Let’s take a look:
root@Router1> show route table BARRYS_ICE_CREAM.inet.0 172.16.20.0/30 BARRYS_ICE_CREAM.inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 172.16.20.0/30 *[BGP/170] 00:02:55, localpref 100, from 11.11.11.11 AS path: 64513 I > to 10.10.12.2 via ge-0/0/0.0, Push 300016, Push 300064, Push 299808(top)
As the traffic goes on its merry way, it will at some stage arrive at R4, who will then of course pass it onto R5. By the time it arrives at Router 4 it only has two labels – the previous top label was used just to get from R1 to R4, so that label is gone now.
With that in mind, Router 4 is going to take the current top label in the stack (300064), and swap it for whatever label R5 told R4 to use. Again, we’ve made some changes to our network, so let’s see what that label is:
root@Router4> show route table mpls.0 label 300064 mpls.0: 12 destinations, 12 routes (12 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 300064 *[VPN/170] 00:06:52 > to 10.10.45.5 via ge-0/0/3.0, Swap 300000
Crikey! 300000? A nice round number!
On the surface, everything seems like it’s working so far. Except… let’s head over to R5, and see what it actually does when it receives a packet with this label:
root@Router5> show route table mpls.0 label 300000 mpls.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 300000 *[VPN/170] 00:06:05 > to 10.10.56.6 via ge-0/0/2.0, Pop 300000(S=0) *[VPN/170] 00:06:05 > to 10.10.56.6 via ge-0/0/2.0, Pop
It pops it!! What??? This means that when the packet gets passed to the physical next-hop (Router 6, in this case), it will be sent with only one label – the VPN label. This label only has a meaning to Router 8, the PE that hosts this VPN prefix. Router 6 will look up this label, find no mapping for it, and discard it. I don’t need to show you the results of a ping on our CPE router to show you that the ping is going to fail!
Why is this happening? This didn’t happen until we made all these new-fangled changes. What’s up?
The logic behind this took me a LONG time to get my head around, but this evening I had a eureka moment. What we’re going to chat about now is what’s known in the industry as “bloody complicated”. So, strap in:
INET.0 vs INET.3
Do you remember what the inet.3 table is used for? It’s used to resolve next-hops for prefixes our router learned by BGP.
In fact, router 5 does indeed have a labeled path to Router 8, in inet.3:
root@Router5> show route 8.8.8.8 inet.0: 16 destinations, 16 routes (16 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 8.8.8.8/32 *[OSPF/10] 01:10:31, metric 3 > to 10.10.56.6 via ge-0/0/2.0 inet.3: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 8.8.8.8/32 *[RSVP/7/1] 01:02:21, metric 3 > to 10.10.56.6 via ge-0/0/2.0, label-switched-path PE5_to_PE8
So, if Router 5 has an LSP to Router 8, why is it popping the traffic?
Here’s the gotcha: when our BGP-LU prefixes were in inet.3, it meant that BGP-LU would take prefixes from inet.3 and advertise them on.
However, now we’re putting our BGP-LU prefixes in inet.0. And as we can see, 8.8.8.8 is being learned by OSPF in the inet.0 table. This means that when Router 5 takes the prefix 8.8.8.8 from inet.0, it has no labelled path to it in this routing table – but nevertheless, it generates a label for it, and sends this label to Router 4.
And for that reason, the solution to our sticky-tricky problem is to get the label-switched path into inet.0. How do we do it? With one simple, beautiful command:
set protocols mpls traffic-engineering mpls-forwarding
We’ve talked about this command in other posts in the past, but to save you time, let’s quickly explain it again: with this one command, we tell our Junos router to copy the contents of inet.3 into inet.0 – but to do it in a “safe” way.
You see, RSVP has a numerically lower, and therefore better, route preference than OSPF. If RSVP wins the fiercely-fought battle for Best Prefix 2019, it can mess up your network in hilarious ways, because the actual best path suddenly isn’t being advertised as the best path (a bit like in Part 1, when we tried redistributing 1.1.1.1 into BGP at Router 1).
To fix this problem, this one command adds the RSVP labeled path into the forwarding table on Router 5, but tricks the routing engine into thinking that the OSPF route is still the best. Here’s what the result looks like:
root@Router5> show route 8.8.8.8 table inet.0 inet.0: 16 destinations, 18 routes (16 active, 2 holddown, 0 hidden) @ = Routing Use Only, # = Forwarding Use Only + = Active Route, - = Last Active, * = Both 8.8.8.8/32 @[OSPF/10] 00:00:29, metric 3 > to 10.10.56.6 via ge-0/0/2.0 #[RSVP/7/1] 00:00:29, metric 3 > to 10.10.56.6 via ge-0/0/2.0, label-switched-path PE5_to_PE8
Now that Router 5 can send traffic destined to 8.8.8.8 via a label-switched path, it can tell Router 4 that if it wants to get to 8.8.8.8, send the packet to R5 with a label of 299776:
root@Router5> show route advertising-protocol bgp 10.10.45.4 8.8.8.8/32 detail inet.0: 16 destinations, 18 routes (16 active, 0 holddown, 0 hidden) @ 8.8.8.8/32 (2 entries, 2 announced) BGP group TO_AS64512 type External Route Label: 299776 {snip}
And what does R5 do when it receives a packet with label 299872? It swaps it for whatever label is advertised on the R5-to-R8 RSVP label-switched path:
root@Router5> show route table mpls.0 label 299872 mpls.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 299872 *[VPN/170] 02:11:00 > to 10.10.56.6 via ge-0/0/2.0, Swap 299808
Hooray! So, now that’s fixed, can CPE 1 ping CPE 2?
CPE_BARRY_1>ping 192.168.20.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.20.1, timeout is 2 seconds: ..... Success rate is 0 percent (0/5) CPE_BARRY_1>
D’oh! We’ve missed something! What is it? For this one, we need to go back to the route reflector.
CONFIGURING OPTION C – ADVERTISING AND LEARNING THE VPN PREFIXES, VIA ROUTE REFLECTORS
We’re running BGP-LU, and we’re putting prefixes in inet.0. Our route reflectors can now route to each other, and so the BGP peering comes up. But what happens when they try to exchange VPN prefixes? Well…
root@Reflector2> show route table bgp.l3vpn.0 hidden bgp.l3vpn.0: 8 destinations, 8 routes (4 active, 0 holddown, 4 hidden) + = Active Route, - = Last Active, * = Both 1.1.1.1:1:172.16.10.0/30 [BGP/170] 01:23:41, localpref 100, from 11.11.11.11 AS path: 64512 I Unusable { snip }
It looks like Reflector 2 is receiving the VPN prefixes from Reflector 1 – but it can’t use them. Why? For the answer, let’s remind ourself about the bgp.l3vpn.0 table – the table that stores all the VPN routes from everywhere, before they’re sorted into the relevant VRFs.
Prefixes in this table require a next-hop that can be resolved in the inet.3 table. There’s the problem: these VPN prefixes have a next-hop of 1.1.1.1, which our router has indeed learned by BGP-LU – but, because of our new configuration changes, this route is placed in the inet.0 table, not the inet.3 table:
root@Reflector2> show route 1.1.1.1 inet.0: 15 destinations, 15 routes (15 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 1.1.1.1/32 *[BGP/170] 00:20:45, MED 1, localpref 100, from 5.5.5.5 AS path: 64512 I > to 10.10.226.6 via ge-0/0/3.0, label-switched-path RR2-to-PE5
Now, in our topology our route reflectors are outside of the path of transit traffic. As such, we can use the same command that we used in our Option B blog post to get around this problem. Let’s add this command to both route reflectors:
set routing-options resolution rib bgp.l3vpn.0 resolution-ribs inet.0
Thanks to this command, our route reflectors will resolve the VPN prefixes in inet.0 – which is exactly where they’ll find all the loopback IP addresses.
And look – when we add it in, Reflector 2 has routes from Reflector 1!
root@Reflector2> show route receive-protocol bgp 11.11.11.11 table bgp.l3vpn.0 detail bgp.l3vpn.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden) * 1.1.1.1:1:172.16.10.0/30 (1 entry, 1 announced) Accepted Route Distinguisher: 1.1.1.1:1 VPN Label: 299840 Nexthop: 1.1.1.1 AS path: 64512 I Communities: target:64512:1 {snip}
Hooray!
How about on our PE routers. Does the fact that our BGP-LU prefixes are in inet.0 cause any problems? Yep! Once again, they need to be in inet.3 for the MPLS VPN to work properly. So, let’s see how we can fix it.
CONFIGURING OPTION C – TEACHING OUR PEs TO RESOLVE VPN PREFIXES
At the moment, Router 8 is going to see VPN prefixes from ISP 1 as having a next-hop of 1.1.1.1. At the moment, thanks to the way we’ve set up BGP-LU, 1.1.1.1 lives only in the inet.0 table. And you and I both know by now that by default, VPN prefixes will only be successfully installed in a VRF if the next-hop can be resolved in inet.3.
As a result of all this, Router 8 knows about the prefixes – but is hiding them:
root@Router8> show route table BARRYS_ICE_CREAM.inet.0 hidden extensive BARRYS_ICE_CREAM.inet.0: 5 destinations, 5 routes (3 active, 0 holddown, 2 hidden) 172.16.10.0/30 (1 entry, 0 announced) BGP Preference: 170/-101 Route Distinguisher: 1.1.1.1:1 Next hop type: Unusable
So, if Router 8 is going to use 1.1.1.1 as a next-hop, 1.1.1.1 needs to be in inet.3.
We fixed this on our route reflectors by telling it to resolve VPN prefixes in inet.0. Now, on our PEs we’ve got all kinds of options available to us for moving/copying/resolving between inet.0 and inet.3. But when we’re using Option C, we don’t need to do anything quite so complicated – instead, there’s a handy command available to us:
set protocols bgp group AS64513 family inet labeled-unicast resolve-vpn
This one command tells the router to copy BGP-LU prefixes (which go into inet.0 by default) into inet.3, as a candidate for resolving VPN routes – but only if the BGP-LU route is being used as a BGP next-hop. Want proof? Sure thing:
root@Router1> show route 8.8.8.8 inet.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 8.8.8.8/32 *[BGP/170] 01:16:20, MED 3, localpref 100, from 11.11.11.11 AS path: 64513 I > to 10.10.12.2 via ge-0/0/0.0, Push 299904, Push 299824(top) inet.3: 6 destinations, 6 routes (6 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both 8.8.8.8/32 *[BGP/170] 00:24:11, MED 3, localpref 100, from 11.11.11.11 AS path: 64513 I > to 10.10.12.2 via ge-0/0/0.0, Push 299904, Push 299824(top)
Aah, would you look at that. A happy ending! So, the big question: does everything finally work again?
CPE_BARRY_1>ping 192.168.20.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.20.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 116/128/156 ms CPE_BARRY_1>
At last!! Everything is working. Now, shall we all agree to never do this in production? Yes? Good.
DOWNLOAD THE FULL CONFIG FILES FOR EACH ROUTER
The config has changed a fair bit on the ISP 2 side of things, so give this a click to download the complete full new configurations. Take a look, try it at home, and play until your heart is “content”.
THAT’S IT!
Wow, that was a long post! Are you really still here? Good work: you’ve officially passed the exam, and earned your NFTCGJ certification (Network Fun-Times Certificate Great Job).
I hope you’ve seen a few new scenarios in this post that you might not have even seen in the official documentation. I hope that the mix of protocols and philosophies in each network have shown you some of the gotchas you might face, and how to overcome them. Now, let’s see how many of these I can remember when I do the JNCIE exam in November! Probably… none? Yeah, I reckon probably none.
If you enjoyed this post then you’d make my world if you shared this post on your favourite social media of choice, or emailed it to friends and colleagues who you think might be interested in it.
If you’re on Mastodon, follow me to find out when I make new posts. (2024 edit: I’m also on BlueSky nowadays too. I was once on Twitter, but I’ve given up on it, on account of… well, I don’t need to finish that sentence, do I.)
And if you fancy some more learning, take a look through my other posts. I’ve got plenty of cool new networking knowledge for you on this website, especially covering Juniper tech and service provider goodness.
It’s all free for you, although I’ll never say no to a donation. This website is 100% a non-profit endeavour, in fact it costs me money to run. I don’t mind that one bit, but it would be cool if I could break even on the web hosting, and the licenses I buy to bring you this sweet sweet content.



Hi Chris,
You mentioned that RSVP requires protocol mpls to be configured, whereas in LDP it is not mandatory, it functions properly without it as well. Could you please explain why it is optional in LDP
Hi there Naufal. Apologies for the slow reply! I’m afraid I don’t know the answer to this. You do still need “family mpls” on the interface, but you don’t need it under the “protocols mpls” hierarchy. I expect it’s something to do with the fact that we also configure RSVP LSPs under the “protocols mpls” hierarchy, instead of the “protovols rsvp” hierarchy – but that’s as much as know.